정규화(normalization)와 표준화(standardization), 머신러닝 성능 향상을 위한 필수 단계
오늘은 꽤 중요한 이야기를 하고자 합니다. 기본적이기 때문에 중요합니다. 이것을 간과하면 성능에 치명적인 영향을 끼치기 때문에 중요합니다. 바로 정규화(normalization)와 표준화(standardization)에 대한 이야기입니다. 정규화와 표준화는 모두 머신러닝 알고리즘을 훈련시키는데 있어서 사용되는 특성(feature)들이 모두 비슷한 영향력을 행사하도록 값을 변환해주는 기술입니다. 이것이 무슨 말인지는 좀 더 읽어보시면 이해가 되실 것입니다.
정규화 또는 표준화는 왜 필요한가?
머신러닝 알고리즘은 기본적으로 데이터를 가지고 무언가를 해내는 친구들입니다. 많은 양의 데이터를 가지고 머신(기계)를 학습시키는 것이 머신러닝, 한국어로는 기계학습이기 때문입니다. 보통 예측하고자 하는 것과 연관이 있을 만한 여러 개의 특성을 가지고 머신러닝 알고리즘을 훈련시킵니다. 예를 들어, 부동산의 가격을 예측하기 위해서 어떤 머신러닝 알고리즘을 훈련시킨다고 가정해보겠습니다.
그렇다면 부동산 가격과 연관이 있을 것과 같은 특성들을 도출(extract)합니다. 집의 평수, 아파트의 나이, 지하철 역과의 거리, 대형마트와의 거리 등이 관련이 있을 것 같습니다. (저는 부동산을 잘 몰라서, 이것들이 실제로 얼마나 집값과 연관이 있는지는 모르겠습니다. 아무튼 그것은 지금 전혀 중요하지 않습니다.) 실제로 존재하는 집의 평수는 10평부터 100평까지 다양할 것입니다. 또한 아파트의 나이는 1년에서 20년, 지하철 역과의 거리는 0.1km부터 1km, 대형마트와의 거리도 1km에서 20km까지 다양할 것입니다.
문제는 '평수', '년', 'km' 등 각 특성의 단위도 다르고, 값의 범위도 꽤 차이가 있다는 것입니다. 우선 단위가 다르면 직접적인 비교가 불가능합니다. 사람의 키와 사람의 몸무게를 직접적으로 비교할 수 없는 것처럼 말이죠.
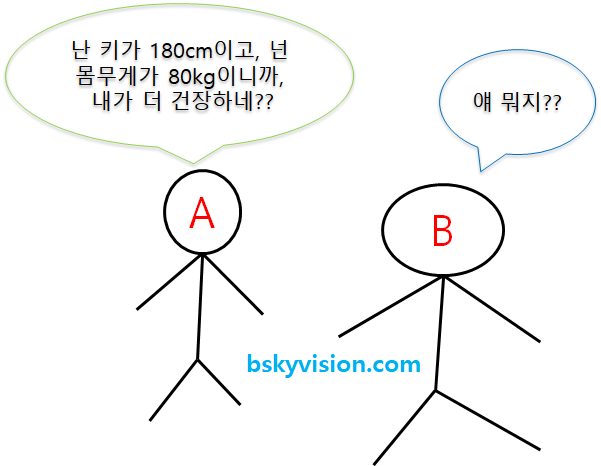
그리고 단위가 같더라도 값의 범위가 크게 차이나는 상황에서도 제대로 비교하는 것이 힘듭니다. 100점 만점에서 90점을 맞는 것과 1000점 만점에서 90점을 맞는 것은 완전히 다른 경우인 것처럼 말이죠.

따라서 특성들의 단위를 무시할 수 있도록, 또한 특성들의 값의 범위를 비슷하게 만들어줄 필요가 있습니다. 그것이 바로 정규화 또는 표준화가 해주는 일입니다. 정규화와 표준화가 해주는 것을 특성 스케일링(feature scaling) 또는 데이터 스케일링(data scaling)이라고 부릅니다.
정규화와 표준화의 차이는 무엇인가?
그렇다면 정규화와 표준화의 차이는 무엇일까요? 정규화(normalization)는 다음과 같은 공식을 사용해서 특성 값의 범위를 [0, 1]로 옮깁니다.
$X' = \frac{X - X_{min}}{X_{max} - X_{min}}$ ...(정규화 공식)
이 공식을 사용하면 한 특성 내에 가장 큰 값은 1로, 가장 작은 값은 0으로 변환됩니다. 이 공식을 이용해서 각 특성들의 값을 변환해주면 모두 [0, 1]의 범위를 갖게 됩니다. 이제야 특성들이 평등한 위치에 놓여진 것입니다.
반면, 표준화(standardization)는 다음과 같은 공식으로 특성들의 값을 변환해줍니다.
$X' = \frac{X - \mu}{\sigma}$ ...(표준화 공식)
여기서 $\mu$는 한 특성의 평균값이고, $\sigma$는 표준편차입니다. 많이 익숙한 공식이죠? 그렇습니다. 고등학교 때 배운 정규분포의 표준화 공식입니다. 표준화는 어떤 특성의 값들이 정규분포, 즉 종모양의 분포를 따른다고 가정하고 값들을 0의 평균, 1의 표준편차를 갖도록 변환해주는 것입니다. 표준화를 해주면 정규화처럼 특성값의 범위가 0과 1의 범위로 균일하게 바뀌지는 않습니다. 아래 박스 플롯들을 보시면 정규화와 표준화를 통해 값의 범위가 어떻게 변하는지를 대략적으로 확인하실 수 있습니다.

정규화와 표준화 중에 어떤 것이 더 나은가?
이 질문에는 쉽게 답하기가 어렵습니다. 케이스 바이 케이스(case by case)이기 때문입니다. 어떤 경우에는 정규화를 해줬을 때 더 좋은 성능을 낼 수 있고, 어떤 경우에는 표준화가 더 나을 수도 있습니다. 따라서 둘 다 해보고 어느 것이 더 나은지 비교해봐야 합니다. 그러나 분명하게 말씀드릴 수 있는 것은 정규화나 표준화를 한 것과 하지 않은 것의 차이는 엄청나게 크다는 것입니다. 따라서, 꼭 해줘야 합니다.
이 글이 도움이 되셨나요? 그렇다면, 공감버튼 한 번 눌러주시면 감사하겠습니다.^^ 또한 질문과 토론에는 항상 열려 있으니 댓글 남겨주시면 살펴보겠습니다. ㅎㅎ
관련 글
[MATLAB] 표준화된 z-점수 산출하기, zscore 함수
[python] SVM 분류 문제를 통해 배우는 머신러닝 훈련 및 테스트
참고자료
[1] https://www.analyticsvidhya.com/blog/2020/04/feature-scaling-machine-learning-normalization-standardization/, Analytics Vidhya, "Feature Scaling for Machine Learning: Understanding the Difference Between Normalization vs. Standardization"
(본문 내 쿠팡 파트너스 링크를 클릭하셔서 물건을 구매하시면 저에게 일정 금액이 후원됩니다.)