[IQA] 구조의 왜곡에 민감하면서, 텍스쳐 리샘플링은 용인해주는 FR-IQA 방법, DISTS
DISTS는 올해(2020년) IEEE Transactions on pattern analysis and machine intelligence에 게재된 논문 "Image Quality Assessment: Unifying Structure and Texture Similarity"에서 제안된 FR-IQA 방법입니다. DISTS는 제목에도 썼듯이 구조의 왜곡에 민감하면서, 텍스쳐 리샘플링은 용인해주는 FR-IQA 방법입니다. 무슨 말인지 모르시겠죠?ㅋㅋ 무슨 말인지 이해가 안되야 정상입니다. 그러니 끝까지 천천히 읽어주세요.^^
먼저 SSIM과 같은 많은 FR-IQA 방법들은 사람의 시각시스템이 이미지의 구조(structure) 변화에 민감하다는 것에 착안해서 이미지의 구조를 나타내는 어떠한 특성맵을 원본 이미지와 왜곡 이미지에서 도출합니다. 그 다음에 그것들이 얼마나 유사한가를 측정합니다. SSIM과 같은 구조의 왜곡에 민감한 방법들은 상당히 잘 작동하는 좋은 FR-IQA 방법입니다. 그런데 어떤 경우에는 잘 작동하지 않습니다. 아래 그림을 보시죠.

첫번째 행의 왜곡 이미지의 경우 SSIM 점수가 0.81입니다. SSIM 점수는 1에 가까울 수록 더 좋은 품질을 나타냅니다. 두번째 행의 왜곡 이미지의 경우 SSIM 점수가 0.30입니다. 사실 두번째 이미지의 경우 원본 이미지와 큰 차이가 없어보이지 않나요?? 그런데 분명한 차이가 있는 첫번째 왜곡이미지보다 두번째 왜곡이미지의 품질을 SSIM은 낮게 평가합니다. 사실 픽셀 단위로 살펴보면 두번째 행의 이미지들이 더 큰 차이가 있습니다. 그런데 사람의 시각시스템은 같은 텍스쳐(이 경우에는 잔디)의 이미지인 경우 실제로는 차이가 있어도 그 차이를 쉽게 인식하지 못합니다. 텍스쳐 리샘플링(texture resampling) 때문입니다. 자세히 살펴보세요. 분명히 같은 잔디지만, 배치에 차이가 있습니다. 그런데 그것을 쉽게 인식하지 못하게 하는 것이 텍스쳐 리샘플링입니다.
이러한 텍스쳐 리샘플링을 용인할 수 있는 FR-IQA 방법이 좀 더 사람이 지각하는 방식을 닮았다고 말할 수 있습니다. 오늘 소개해드리는 DISTS가 바로 그것을 추구한 방법입니다. DISTS는 어떻게 만들어졌길래 텍스쳐 리샘플링도 이해할 수 있을까요? 바로 다음과 같은 알고리즘을 갖고 있습니다.
우선 원본 이미지와 왜곡 이미지를 이미지넷에 미리 훈련된 VGG16에 통과시킵니다. 거기서 얻은 딥 특성맵들과 입력 이미지들의 유사도를 각각 두 개의 metric으로 측정합니다. 하나의 metric은 원본 이미지의 딥 특성맵과 왜곡 이미지의 딥 특성맵의 평균을 비교하는 것입니다. 이것은 텍스쳐의 유사도를 측정하기 위해 사용됩니다. 또 하나의 metric은 원본 이미지의 딥 특성맵과 왜곡 이미지의 딥 특성맵의 correlation을 비교하는 것입니다. 이것은 구조의 유사도를 측정하기 위해 사용됩니다.
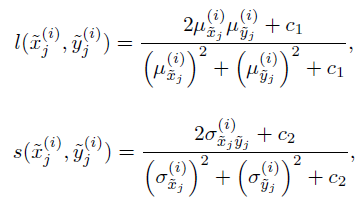
결과적으로 입력 이미지를 비교함으로 3개의 l 점수, 3개의 s 점수를 얻게 되고(r, g, b 채널 이미지), 64개+128개+256개+512개+512개의 l 점수 및 s 점수를 얻게 됩니다. 그것들에 가중치들을 부여해서 모두 합한 다음에 1에서 뺌으로 최종 점수를 얻게 됩니다.

그 가중치 알파들과 베타들은 훈련을 통해 얻습니다. 알파와 베타를 훈련시킬 때, 두 개의 손실함수를 합한 것을 사용하는데 하나는 이미지품질평가 데이터과 연관된 것이고, 다른 하나는 텍스쳐분류 데이터셋과 연관된 것입니다. ground-truth 이미지 품질 라벨과 예측된 D 사이의 절대차가 작아지도록 알파와 베타가 조정되는 동시에, 텍스쳐가 같은 것에 대해서는 D가 작아지도록 알파와 베타를 조정합니다. 그렇기 때문에 DISTS는 결과적으로 구조적 변화에 민감함을 유지하면서 텍스쳐 리샘플링은 용인하게 되는 것이죠.