[IQA] DeepFL-IQA (2020년) 알고리즘 설명
올해(2020년) TMM에 게재된 IQA 알고리즘 DeepFL-IQA에 대해 간략히 설명드리도록 하겠습니다. 논문의 제목은 "DeepFL-IQA: Weak Supervision for Deep IQA Feature Learning"입니다.
이 알고리즘은 크게 두 단계로 분류할 수 있습니다. 첫번째 단계에서는 multi-task learning(MTL)을 적용해서 11개 FR-IQA 점수들을 예측하는 네트워크를 만듭니다. 미리 훈련된 InceptionResNetV2에 이미지를 통과시켜서 얻은 1536개의 특성맵들에 GAP(global average pooling)을 적용해서 1536개의 값을 얻습니다. 그것을 11개의 FC512-FC256-FC1 모듈에 연결시킵니다. 각 모듈은 하나의 FR-IQA 점수를 라벨로 삼습니다. 이 첫번째 단계의 네트워크는 KADIS-700k 데이터셋으로 훈련됩니다. KADIS-700k 데이터셋은 DMOS나 MOS와 같은 주관평가점수를 제공하지 않습니다. 대신, 11개의 FR-IQA 방법의 점수들이 라벨의 역할을 하는 것입니다. 논문 제목에 weak supervision이라는 내용이 들어간 것도 이 때문이라고 할 수 있습니다. 비교적 구하기 힘든 DMOS, MOS 대신에 11개의 FR-IQA 점수를 라벨로 삼았기 때문입니다.

첫번째 단계가 완수되면, 두번째 단계로 진입합니다. 첫번째 단계를 통해 InceptionResNetV2 내의 가중치들이 업데이트 되었습니다. 그러면, 이제 그 InceptionResNetV2에 이미지를 통과시킵니다. 생성된 모든 특성맵(16928개)을 활성화시킨 후에 GAP를 이용해서 16928개의 특성을 도출합니다.
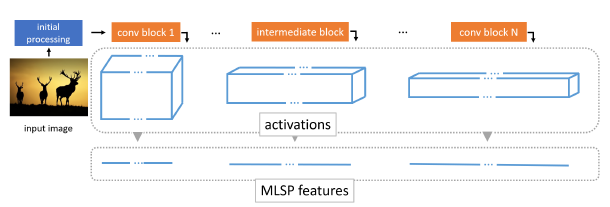
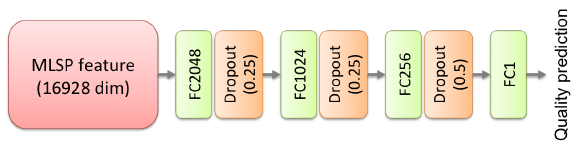
그 특성을 논문에서는 MLSP(multi-level spatially pooled) 특성이라고 부릅니다. 16928개의 특성을 regression 모델을 훈련시키는데 사용합니다. 저자들은 아래와 같은 형태의 인공신경망을 regressor로 사용했습니다. regressor를 훈련시킬 때는 IQA 데이터베이스의 주관평가점수를 라벨로 삼았습니다.
저자들은 그들이 새롭게 만든 IQA 데이터베이스인 KADID-10k를 이 논문에서 소개하기도 합니다. 데이터베이스에 대한 설명은 따로 해놓았으니 링크를 참고하시기 바랍니다.
논문과 관련해서 디테일한 내용은 해당 논문을 참고하시고, 질문이나 의문이 있으면 댓글로 남겨주시면 감사하겠습니다. 항상 말씀드리는 것이지만 제 설명이 틀렸을 수도 있으니 잘못된 설명은 꼭 지적해주시기 바랍니다.