오늘은 판다스의 merge 함수와 데이터프레임의 join 메소드를 비교해보도록 하겠습니다. 우선 둘다 SQL의 JOIN과 비슷한 기능을 하는 친구들입니다.
pd.merge() vs df.join()
판다스의 merge 함수
예제에 사용하기 위해 두 개의 데이터 프레임을 먼저 준비했습니다.
import pandas as pd
df1 = pd.DataFrame({'id':[1, 2, 3, 4], 'name':["심교훈", "문태호", "황병일", "이정기"]})
df2 = pd.DataFrame({'id':[1, 3, 5, 6], 'hobby':['숨쉬기', '농구', '기타', '뜨개질']})
print(df1, '\n')
print(df2, '\n')

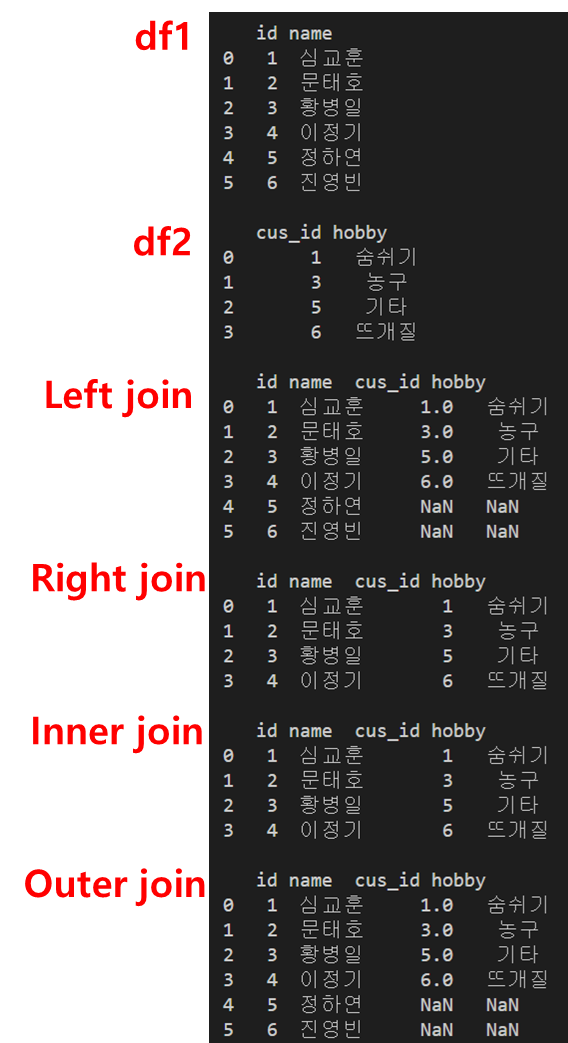
두 데이터프레임을 pd.merge() 함수를 사용하여 join 해보겠습니다.
inner 조인
merged_df = pd.merge(df1, df2, how='inner', on='id')
print(merged_df, '\n')
df1과 df2에서 id 컬럼의 값이 같은 행끼리 결합된 것을 확인하실 수 있습니다.

join의 4가지 방식 중에서 inner join의 방식으로 결합된 것입니다.

left 조인
join의 방식을 바꾸고 싶으면 how 옵션의 값을 달리해주면 됩니다. left join 방식을 취하고 싶으면 how='left' 옵션을 추가해주면 됩니다.
merged_df = pd.merge(df1, df2, how='left', on='id')
print(merged_df, '\n')
왼쪽 데이터프레임을 기준으로 결합되었고 id=2, 4인 행은 오른쪽 데이터프레임에 존재하지 않기 때문에 hobby 컬럼에 NaN 값들이 들어갔습니다.

right 조인
이번에는 right join 방식을 취해보겠습니다.
merged_df = pd.merge(df1, df2, how='right', on='id')
print(merged_df, '\n')
outer 조인
이번에는 outer 조인 방식으로 결합해보겠습니다.
merged_df = pd.merge(df1, df2, how='outer', on='id')
print(merged_df, '\n')

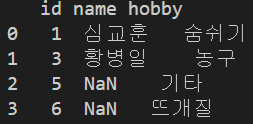
두 데이터프레임에서 결합의 기준으로 삼아야 하는 컬럼의 이름이 다른 경우
만약 두 데이터프레임에서 결합의 기준으로 삼고 싶은 컬럼의 이름이 다르다면, left_on='컬럼명', right_on='컬럼명'을 추가로 넣어주면 됩니다. 아래 예제 코드는 왼쪽 데이터프레임의 id 컬럼과 오른쪽 데이터프레임의 cus_id 컬럼을 결합해야 하는 상황입니다.
df1 = pd.DataFrame({'id':[1, 2, 3, 4], 'name':["심교훈", "문태호", "황병일", "이정기"]})
df2 = pd.DataFrame({'cus_id':[1, 3, 5, 6], 'hobby':['숨쉬기', '농구', '기타', '뜨개질']})
print(df1, '\n')
print(df2, '\n')
merged_df = pd.merge(df1, df2, how='inner', left_on='id', right_on='cus_id')
print(merged_df, '\n')
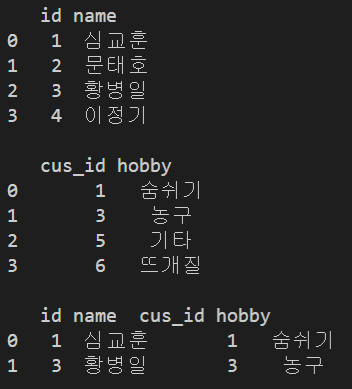
데이터프레임의 join 메소드
df.join() 메소드도 pd.merge() 함수와 비슷한 기능을 합니다. 다만 행 인덱스를 기준으로 결합을 해줍니다. 이것도 how 옵션을 통해 left, right, inner, outer join 방식을 취할 수 있습니다.
df1 = pd.DataFrame({'id':[1, 2, 3, 4, 5, 6], 'name':["심교훈", "문태호", "황병일", "이정기", "정하연", "진영빈"]})
df2 = pd.DataFrame({'cus_id':[1, 3, 5, 6], 'hobby':['숨쉬기', '농구', '기타', '뜨개질']})
print(df1, '\n')
print(df2, '\n')
joined_df = df1.join(df2, how='left')
print(joined_df, '\n')
joined_df = df1.join(df2, how='right')
print(joined_df, '\n')
joined_df = df1.join(df2, how='inner')
print(joined_df, '\n')
joined_df = df1.join(df2, how='outer')
print(joined_df, '\n')
행 인덱스를 기준으로 잘 결합되었습니다.
관련 글
- [sqlite3] JOIN으로 서로 다른 테이블의 컬럼들 붙이기(내부 조인, 외부 조인)
참고자료
[1] https://pandas.pydata.org/docs/reference/api/pandas.merge.html
'Dev > python' 카테고리의 다른 글
| [python] 딕셔너리 키 리스트, 값 리스트 생성하기 (7) | 2022.09.06 |
|---|---|
| [python, opencv] 이미지에 한글 텍스트 삽입하기, pillow 활용 (0) | 2022.09.04 |
| [flask] Ajax로 json 데이터 post 전달시 flask 서버 get_json() 관련 오류 해결 방법 (0) | 2022.08.29 |
| [python] 함수를 매개변수로 전달할 때 많이 사용되는 람다(lambda) (2) | 2022.08.23 |
| [pandas] 파이썬 판다스로 엑셀 파일을 읽고 쓰려면 openpyxl도 추가로 설치해야 함 (0) | 2022.08.15 |
| [flask+jinja2] flask 프로젝트에서 html에 이미지 삽입하는 방법 (0) | 2022.08.09 |
| [PyQt6] pyqt 앱 윈도우 크기 고정 방법 (0) | 2022.08.05 |
| [python] playsound 라이브러리 playsound.PlaysoundException: Error 259 for command 예외 해결 방법 (2) | 2022.08.04 |