image classification은 이미지가 개에 관한 것인지, 고양이에 관한 것인지, 사람에 관한 것인지, 자동차에 관한 것인지 분류하는 컴퓨터 비전 과제다. 그렇다면 fine-grained image classification은 무엇일까? 새의 종, 꽃의 종, 동물의 종 또는 자동차의 모델 같이 구분하기 어려운 클래스들을 분류하는 과제다. 사람에게는 image classification보다 당연히 좀 더 어려운 과제이다. 직관적으로 생각해도 자동차와 꽃을 분류하는 것보다 참새인지, 독수리인지, 앵무새인지를 구분하는 것이 좀 더 어려울 것이다. 왜냐하면 비슷하게 생겼기 때문이다.
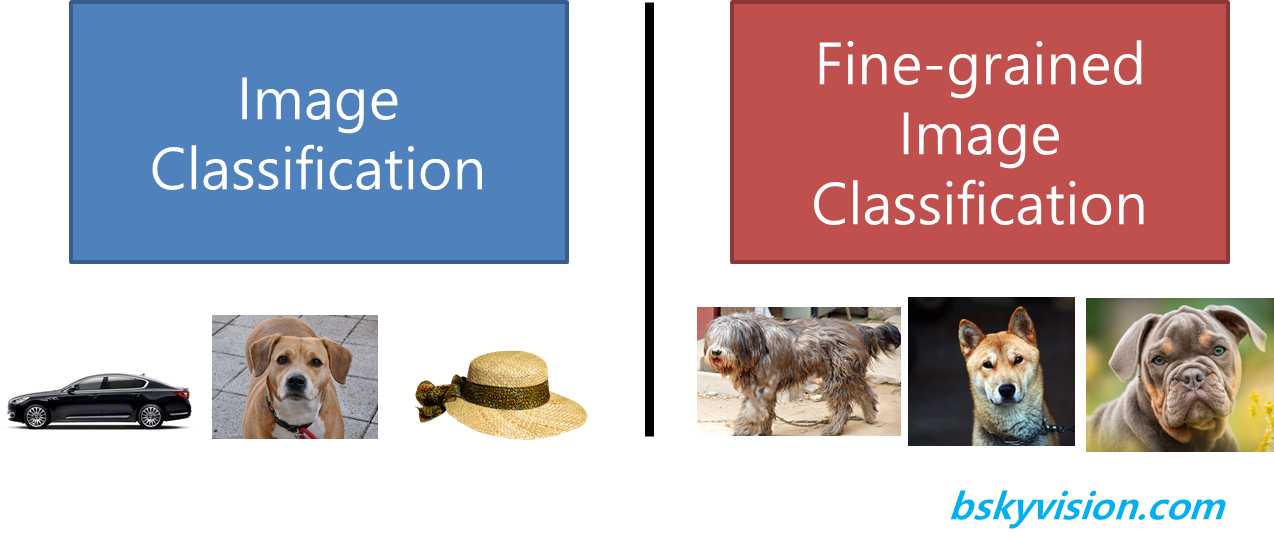
얼마 전에 아는 형님의 남자 아이와 통화를 하는데 자동차가 어떤 브랜드인지 무슨 모델인지에 대해서 너무나 잘 분류해내는 것을 보고 신기했다. 포드인지, BMW인지, 기아인지, 현대인지, 도요타인지 대번에 아는 것 아닌가? 그 아이는 fine-grained image classification 능력이 뛰어난 것이다. 나보다 훨씬 더 잘 구분해낸다.
image classification의 대표 데이터셋이 이미지넷(ImageNet)이라면, fine-grained image classfication에 자주 사용되는 데이터셋에는 CUB-200-2011, Stanford Cars, Stanford Dogs 등이 있다. CUB-200-2011은 200개의 클래스를 포함하고, 5994개의 훈련셋과 5794개의 테스트셋으로 구성되어 있다. Standford Cars는 196개의 클래스, 8144개의 훈련셋, 8041개의 테스트셋을 제공한다. Stanford Dogs의 경우에는 120개 클래스, 12000개 훈련셋, 8580개 테스트셋을 갖는다.
<참고자료>
[1] https://paperswithcode.com/task/fine-grained-image-classification, paperswithcode, "Fine-Grained Image Classification"
'Research > 컴퓨터비전, 영상처리' 카테고리의 다른 글
| [IQA] 이미지 내 지배적인 구조가 왜곡되면 지각 품질이 나쁘다, DASM (0) | 2019.12.17 |
|---|---|
| [IQA] 2D 이미지 품질 평가 데이터베이스들: LIVE, CSIQ, TID2013 (2) | 2019.12.16 |
| [IQA] visual masking 현상을 고려한 IQA 알고리즘, MAD (1) | 2019.12.10 |
| [IQA] 표준편차 풀링을 제안한 GMSD, 빠름 주의 (2) | 2019.12.09 |
| 이미지 캡셔닝(image captioning), 이미지에 자동으로 캡션을 달아주자 (4) | 2019.11.19 |
| [IQA] 왜곡으로 인한 LBP(local binary pattern)의 변화를 이용한 알고리즘, NRSL (0) | 2019.11.18 |
| [IQA] 가상의 참조 이미지를 만들어서 평가에 활용하는 NR 방식 알고리즘, BMPRI (0) | 2019.11.12 |
| [IQA] 저주파 신호의 왜곡에 더 민감하단 특성을 이용한 UQI-HVS (0) | 2019.11.11 |