머신러닝 모델의 성능을 평가하는 방법은 크게 두가지로 나눌 수 있습니다. 하나는 hold-out 교차검증이고 하나는 k-fold 교차검증입니다. 제가 주로 연구하는 이미지품질평가 분야에서는 hold-out 교차검증을 주로 채택합니다. 그리고 시각품질편안도평가 분야에서는 k-fold 교차검증을 주로 활용하구요. 문헌조사를 통해 자신이 연구하는 분야에서 보통 어떤 검증 방법을 채택하는지를 살펴본 후 그것을 이용하면 됩니다. 그러면 이제 hold-out 교차검증과 k-fold 교차검증에 대해서 하나씩 살펴보도록 하겠습니다.
hold-out 교차검증
hold-out은 데이터셋을 훈련셋과 테스트셋으로 분리합니다. 예를들어, 데이터셋의 80%를 훈련셋으로 삼아 모델을 훈련시키고, 나머지 20%를 테스트셋으로 이용해서 성능을 평가하는 것이죠. 그런데 훈련셋과 테스트셋으로만 나눠서 모델의 성능을 평가하다보면, 테스트셋이 모델의 파라미터 설정에 큰 영향을 미치게 됩니다. 모델이 테스트셋에 오버피팅될 가능성이 있게 되는 것이죠.

그래서 데이터셋을 훈련셋과 테스트셋으로만 나누기 보다는 훈련셋, 검증셋, 테스트셋 이렇게 세개로 나누는 것을 권장합니다. 훈련셋을 이용해서 모델을 훈련시키고, 검증셋으로 모델의 최적 파라미터들을 찾아가고, 그 다음에 테스트셋을 이용해서 모델의 성능을 평가하는 것이죠. 이렇게 해주면, 테스트셋은 모델의 훈련과 성능을 높여주는 과정과는 무관하기 때문에 좀 더 나은 검증방법이라고 볼 수 있습니다.

k-fold 교차검증
k-fold 교차검증은 데이터셋을 k개의 서브셋으로 분리합니다. 5-fold면 5개의 서브셋으로 분리해주는 것이죠. 그 다음에 하나의 서브셋만 테스트에 사용하고 나머지 k-1개의 서브셋은 훈련에 사용합니다. 이것을 k번 반복합니다. 다음 그림과 같은 방식으로 말이죠. 이렇게 k번 측정한 성능지표를 평균냄으로 최종적으로 모델의 성능을 평가합니다.
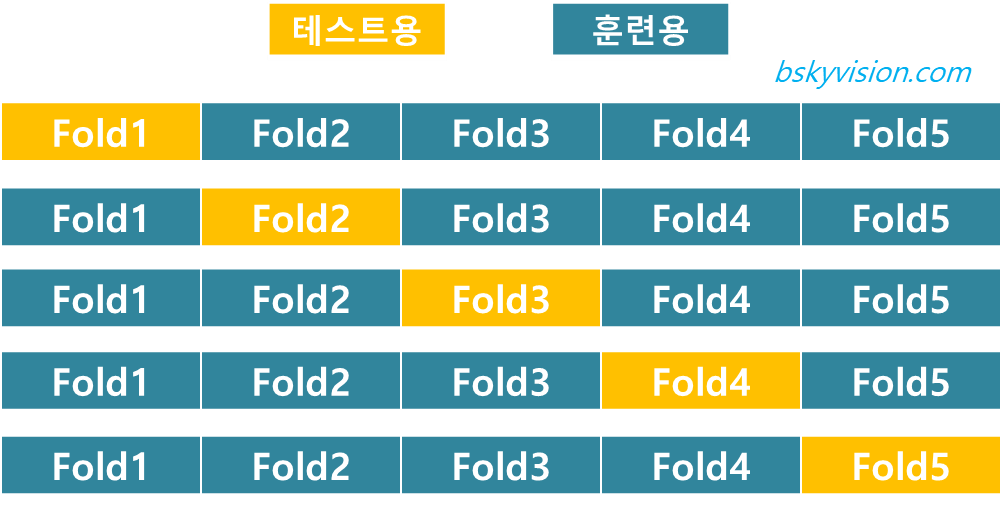
만약 데이터셋의 크기가 별로 크지 않다면, 데이터셋의 샘플을 랜덤하게 섞어준 다음에 hold-out 교차검증이나 k-fold 교차검증을 해줍니다. 샘플을 섞어주고 검증하는 과정을 여러번 반복해서(10번 or 100번 or 1000번) 얻은 성능지표들을 평균내어 성능을 평가하기도 합니다. 이렇게 해주면 좀 더 제대로 모델을 평가할 수 있죠.
끝까지 읽어주셔서 감사합니다. 항상 질문과 지적은 환영합니다. 빠르게 답변드리고 있으니 댓글 남겨주세요.
참고자료
[1] https://medium.com/@eijaz/holdout-vs-cross-validation-in-machine-learning-7637112d3f8f, Eijaz Allibhai, "Hold-out vs. Cross-validation in Machine Learning"
[2] wooono.tistory.com/105, 최운호님, "[ML] 교차검증 (CV, Cross Validation)이란?"
(이 글은 2021-2-14에 마지막으로 수정되었습니다.)
'Research > ML, DL' 카테고리의 다른 글
| 딥러닝 손실 함수(loss function) 정리: MSE, MAE, binary/categorical/sparse categorical crossentropy (4) | 2020.06.24 |
|---|---|
| 배치(batch)와 에포크(epoch)란? (5) | 2020.06.11 |
| ground-truth 라벨을 얻기 어려운 경우 대안, pseudo 라벨 (0) | 2020.04.15 |
| 손실함수(loss)와 평가지표(metric)란? 그 차이는? (0) | 2020.04.07 |
| [object detection] Fast R-CNN의 구조 (13) | 2020.02.07 |
| [object detection] R-CNN의 구조 (4) | 2020.02.05 |
| 전이학습(transfer learning) 재밌고 쉽게 이해하기 (4) | 2020.02.04 |
| [CNN 알고리즘들] SENet의 구조 (4) | 2020.01.31 |