컴퓨터비전에서 어떤 연구 과제이든 관계없이 컨볼루션 신경망(convolutional neural network, CNN)은 중요하게 사용되고 있습니다. 이미지품질평가(image quality assessment, IQA) 과제에서도 마찬가지입니다. 오늘 이 포스팅에서는 CNN을 사용하는 IQA 모델에는 어떤 것들이 있는지, 또 어떻게 사용되고 있는지를 요약 정리하고자 합니다. IQA 모델은 원본 이미지를 참고할 수 있는지 여부에 따라 세 종류로 나눌 수 있습니다: Full-reference (FR) 방법, Reduced-reference (RR) 방법, No-reference (NR) 방법. FR 방법은 원본 이미지에 대한 전체 정보가 필요한 방법이고, RR 방법은 원본 이미지에 대한 일부 정보가 필요한 방법이고, NR 방법은 원본 이미지 없이도 작동하는 방법입니다. NR 방법이 가장 활용도가 높지만, 현재까지는 FR 방법들이 가장 안정적이고 신뢰도가 높아 이미지 압축, 비디오 스트리밍 등에 실제로 활용되고 있습니다. 자, 그러면 CNN 기반 IQA 모델에 대해서 시간순으로 소개시켜드리도록 하겠습니다.
*(2014 CVPR) Le Kang, "Convolutional Neural Networks for No-Reference Image Quality Assessment"
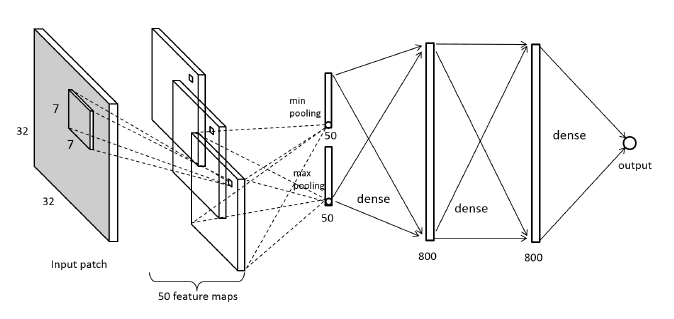
Le Kang 등은 1층의 컨볼루션 (Conv) 레이어와 3층의 fully connected (FC) 레이어로 이뤄진 NR IQA 모델을 제시했습니다. 먼저 이미지를 32 x 32 사이즈의 패치로 중첩되지 않게 분할해줍니다. 각 이미지 로컬 패치를 50개의 필터 커널로 컨볼루션해줘서 50장의 특성맵을 산출해냅니다. 각 특성맵의 최소값을 계산해준 것들과 최대값을 계산해준 것들을 하나의 벡터로 해서 fully connected 레이어에 연결시켜줍니다. 최종 아웃풋 노드를 통해 하나의 로컬 패치에 대한 품질 점수가 예측됩니다. 그 로컬 패치들의 품질 점수를 평균냄으로 이미지 전체에 대한 품질을 예측했습니다.
노트:
- 전처리 단계에서 MSCN으로 이미지를 표준화해줌.
- Stochastic gradient decent (SGD) 최적화방법을 사용.
- 두번째 FC 레이어에 dropout 적용.
- 각 로컬 패치의 라벨값도 전체 이미지의 라벨값으로 해줌.
- ReLU 활성화 함수를 사용하지 않았음.
- validation set에서 모델의 성능을 평가할 때는 LCC(linear correlation coefficient)를 사용함.
*(2015 Signal, Image and Video Processing) Jie Li, "No-reference image quality assessment using Prewitt magnitude based on convolutional neural networks"
Jie Li 등은 각 로컬 이미지 패치의 품질 점수를 CNN을 통해 예측했습니다. 또한 그래프 기반 이미지 분할 알고리즘으로 이미지들을 분할한 후에, 분할된 이미지의 Prewitt gradient 맵을 계산했습니다. gradient 크기를 패치에 따라 평균낸 것을 가중치로 삼아서 로컬 품질 점수들을 종합함으로 최종 품질 점수를 구했습니다.
노트:
- MSCN으로 표준화해줌.

*(2017 Neurocomputing) Fei Gao, "DeepSim: Deep similarity for image quality assessment"
Fei Gao 등은 이미지 분류 과제를 위해 미리 훈련된 딥러닝 모델을 특성맵 도출에 사용하는 FR IQA 모델을 제안했습니다. 미리 훈련된 VGG16 모델에 원본 이미지와 왜곡 이미지를 각각 입력해서 아주 많은 수의 원본 특성맵들과 왜곡 특성맵들을 얻었습니다. 그 다음에 원본 특성맵들과 그에 해당하는 왜곡 특성맵들의 유사도를 SSIM을 이용해서 산출한 다음에 그 유사도들을 평균냄으로 이미지에 대한 품질 점수를 예측했습니다.

*(2018 Signal, Image and Video Processing) Simone Bianco, "On the Use of Deep Learning for Blind Image Quality Assessment"
Simone Bianco 등은 ImageNet 데이터셋과 Place 데이터셋을 합친 데이터로 미리 훈련된 CNN 모델을 이미지품질 데이터셋을 이용해서 fine-tuning한 모델을 이용해서 특성을 도출했습니다. 전이학습(transfer learning)을 이용한 것이죠. fine-tuning 과정에서 이미지 품질 점수를 5개의 카테고리(bad, poor, fair, good, excellent)로 분할해서 분류기를 훈련시키는 방식으로 모델을 훈련시켰습니다. 도출된 특성은 SVR(support vector regressor)을 훈련시키는데 사용되고, 최종적으로 품질 점수가 예측됩니다.
*(2018 TIP) Kede Ma, "End-to-End Blind Image Quality Assessment Using Deep Neural Networks"
Kede Ma 등은 이미지 내 존재하는 왜곡의 유형과 정도를 동시에 예측해내는 NR IQA 모델을 제안했습니다. 왜곡 이미지는 4층의 Conv 레이어를 거친 후에 먼저 서브네트워크1에 입력되어 왜곡의 유형을 예측합니다. 또한 4층의 Conv 레이어를 거쳐 얻게된 특성정보는 서브네트워크1에서 얻은 왜곡 유형과 함께 서브네트워크2에 입력되고, 최종적으로 품질 점수가 예측됩니다.
공유 레이어들은 서브네트워크1과 함께 pre-train 됩니다. 그러고 나서 서브네트워크2를 훈련시킬 때 전체 네트워크의 가중치들이 최적화됩니다.
노트:
- GDN(generalized divisive normalization)을 활성화 함수로 사용.
- Adam 최적화방법을 사용.
- 4개의 왜곡 유형(JP2K, JPEG, WN, Blur)을 가진 이미지들로만 훈련과 테스트를 수행함.

*(2018 TIP) Sebastian Bosse, "Deep Neural Networks for No-Reference and Full-Reference Image Quality Assessment"
Sebastian Bosse 등은 깊은 구조를 가지는 CNN 기반의 FR IQA 모델과 NR IQA 모델을 제안합니다. 여기서는 NR IQA 모델에 대해서만 다루도록 하겠습니다. 먼저 10층의 Conv 레이어를 이용해서 이미지 로컬 패치에 대한 특성을 도출합니다. 그 다음에 2층의 FC 레이어를 이용해서 각 로컬 패치의 품질 점수와 시각적 중요도를 예측합니다. 각 패치의 중요도에 따라 로컬 패치의 품질 점수들을 가중합하여 최종 품질 점수를 산출합니다.
노트:
- Adam 최적화방법을 사용.

*(2018 TIP) Hossein Talebi, "NIMA: Neural Image Assessment"
Hossein Talebi 등은 이 논문에서 IQA에 사용될 수 있는 모델과, IAQA 과제에 사용될 수 있는 모델, 즉 두 개의 모델을 제안합니다. IQA와 IAQA 과제의 차이는 링크건 글을 참고해주세요. 보통은 IQA만을 위한 모델을 만들거나, IAQA만을 위한 모델을 만들거나 둘 중 하나인데, 이 논문은 둘 다 만든 것이죠. 이 논문은 기술적으로는 그렇게 어렵지는 않습니다. 이 방법도 이미지 분류 데이터셋에서 훈련된 모델을 다른 과제에 사용하는 전이학습(transfer learning)을 이용하는데, fine-tuning을 해줄 때 IQA 데이터셋을 이용해서 하냐 아니면 IAQA 데이터셋을 이용하는가 하는 차이죠.
그런데 저자들이 제안한 방법은 기존의 IQA 또는 IAQA 방법들과는 조금 다른 점이 있습니다. 모델을 훈련시킬 때 주관 평가 점수들의 평균값 즉, MOS나 DMOS로 하는 것이 아니라, 주관 점수의 분포를 이용해서 모델을 훈련시킵니다. 또한 품질 점수를 하나의 스칼라 값으로 매기지 않고, 또한 예측된 점수들의 분포로 나타냅니다. 이렇게 하는 것이 꽤 합리적이라고 생각되는 것이 이미지의 품질에 대한 주관적 평가를 평균내서 하나의 점수로 나타낸다는 것은 어쩌면 적합하지 않을 수 있기 때문입니다. 항상 주관 평가가 분산의 정도가 같은 가우시안 분포를 가진다면 모르겠지만, 대부분의 경우 주관 점수의 분산이 꽤 다를 수 있기 때문입니다. 그래서 하나의 점수 대신, 점수의 분포를 히스토그램의 형태로 출력해준다면 좀 더 공정한 평가를 내림과 동시에 유익한 정보를 줄 수 있는 것이죠.
노트:
- IQA 과제를 위해서는 pretrained VGG16 모델을 사용했고, IAQA 과제를 위해서는 pretrained Inception-v2 모델을 사용함.
- IQA용 모델의 fine-tuning에는 TID2013 데이터셋을, IAQA용 모델의 fine-tuning에는 AVA(aesthetic visual analysis) 데이터셋을 사용함.
- 손실 함수로 squared EMD(earth mover's distance)를 사용함.

-----
지금까지 2014년부터 2018년까지 학계에 소개된 CNN을 활용하는 IQA 모델들에 대해서 요약해봤습니다. 물론 이것말고도 훨씬 더 많이 있습니다. 저는 그 중에서 인상적이었던 논문들만 먼저 소개시켜드렸고, 추후에 몇개의 모델에 대한 설명을 추가할 예정입니다. 유익하셨다면 공감과 댓글을 남겨주시기 부탁드리며, 이 글을 마치도록 하겠습니다.^^
'Research > 컴퓨터비전, 영상처리' 카테고리의 다른 글
| 가상현실(VR) 영상 촬영부터 시청까지 (3) | 2020.05.13 |
|---|---|
| 인공지능 기술이 선(善)용된 예와 악(惡)용된 예 (0) | 2020.04.16 |
| [IQA] 이미지품질평가 모델 개발에 대한 세가지 접근법: 상향식, 하향식, 데이터 중심 (0) | 2020.04.13 |
| 초해상화(Super-resolution)란? 저화질 영상을 고화질로 바꿔주는 기술 (7) | 2020.04.11 |
| 이미지품질평가(IQA)와 이미지미적품질평가(IAQA)의 차이 (0) | 2020.04.08 |
| HDR(high dynamic range) 이미지와 톤매핑(tone-mapping) (8) | 2020.02.10 |
| 이미지 리타겟팅(image retargeting)이란? (0) | 2020.01.08 |
| Harris 코너 검출기의 이해 (2) | 2019.12.23 |