이번 시즌에 높은 타율을 기록했던 선수는 다음 시즌에도 비슷한 타율을 기록할 수 있을까요? 둘 사이에는 얼마나 큰 상관관계가 있을까요? 즉, 타율은 선수의 실력과 관계가 클까요? 아니면 운과 관계가 클까요? 타율이 타자의 실력을 잘 반영하는 것이라면, 매년 비슷한 수치가 나올 것이고, 특정 시즌의 타율과 그 다음 시즌의 타율 사이의 상관관계는 클 것입니다. 그렇지 않고, 타율이 운에 의해 좌지우지 되는 것이라면, 매년 꽤 다른 수치를 기록할 것이고, 특정 시즌의 타율과 그 다음 시즌의 타율 사이의 상관관계는 작을 것입니다. 참고로 자신의 기록들간의 상관관계를 자기상관(auto-correlation)이라고 부릅니다.
연속된 두 시즌의 타율 사이의 상관관계
먼저 연속된 두 시즌의 타율 사이의 상관관계부터 살펴보겠습니다. 저는 MLB 데이터에서 1990년부터 2019년까지의 타자 기록 중에 시즌 타수가 2년 연속 250이상인 선수들의 기록을 대상으로 분석을 실시했습니다. 하나의 점은 어떤 한 선수의 특정 시즌 타율(x축)과 그 다음 시즌 타율(y축)을 나타냅니다.
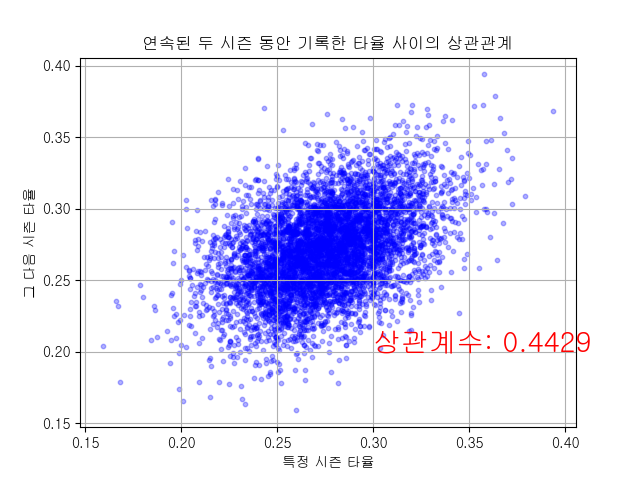
보시다시피 직전 시즌과 다음 시즌의 타율 사이에는 상관관계가 있긴 하지만 강하지 않습니다. 타율이라는 것은 실력의 영향을 받지만, 운의 영향도 꽤 많이 받는다는 뜻입니다. 따라서 타자들의 다음 시즌의 타율은 예측하기 쉽지 않습니다.
연속된 두 시즌의 OPS 사이의 상관관계
이번에는 OPS를 살펴보겠습니다.
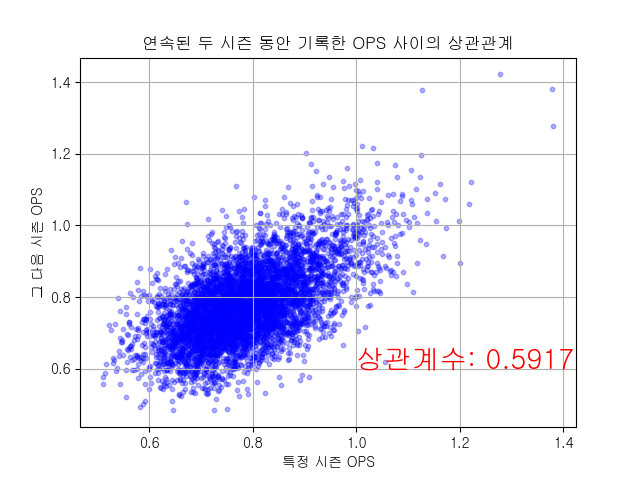
직전 시즌의 OPS와 다음 시즌의 OPS 사이의 상관계수 역시 그렇게 높진 않습니다. 0.5917로 타율의 그것보다는 높지만요. OPS 역시 실력과 운의 영향을 동시에 많이 받는 스탯이라고 볼 수 있습니다.
연속된 두 시즌의 삼진 비율 사이의 상관관계
그러면, 어떤 스탯이 비교적 예측 가능한 것일까요? 타석당 삼진 비율(K%)을 살펴보겠습니다.
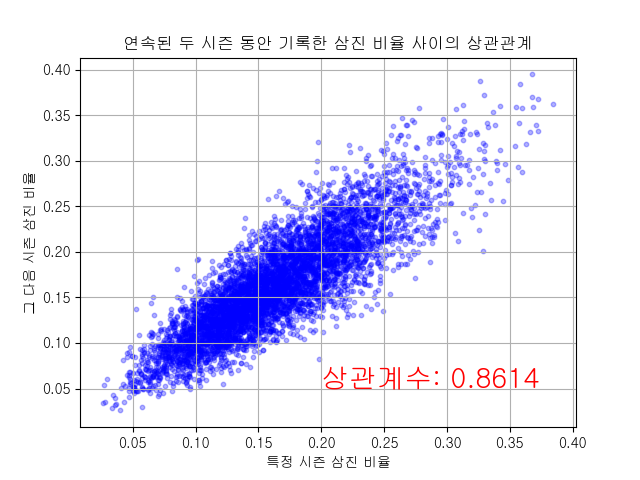
0.8614의 높은 상관계수가 나왔습니다. 이 말인즉슨, 삼진 비율은 실력의 영향을 아주 많이 받는다는 것입니다. 삼진을 많이 당한 선수는 다음 시즌에도 삼진을 많이 당할 가능성이 큽니다. 반면 적게 당한 선수는 다음 시즌에도 역시 적게 당할 가능성이 큽니다. 따라서 삼진 비율은 타율과 OPS 보다 예측 가능한 신뢰도가 높은 스탯입니다.
연속된 두 시즌의 볼넷 비율 사이의 상관관계
마지막으로 타석당 볼넷 비율(BB%)에 관해서 살펴보겠습니다.

볼넷 비율도 꽤 강한 자기상관을 가집니다. 삼진 비율에 비하면 약하긴 하지만요. 볼넷을 많이 얻는 선수는 다음 시즌에도 볼넷을 많이 얻을 가능성이 있습니다. 볼넷 비율도 삼진 비율과 마찬가지로 어느 정도 예측이 가능합니다.
고찰
타율 < OPS < 볼넷 < 삼진 순으로 자기상관이 강했습니다. 이 결과를 잘 생각해보면, 눈 야구가 방망이 야구보다 좀 더 믿을 만한 것이라고 말할 수 있습니다. 타율보다 OPS(=출루율 + 장타율)가 좀 더 예측 가능한 지표인 이유도 OPS에는 눈 야구의 영향을 많이 받는 출루율이 포함되어 있기 때문입니다.
여러 시즌을 치른 배테랑 선수의 경우, 다음 시즌의 타율을 어느 정도 예측할 수 있겠지만, 1-2년차 신인의 경우에는 다음 시즌의 타율을 예상하기 쉽지 않습니다. 하지만, 다음 시즌의 삼진 비율과 볼넷 비율은 타율, OPS에 비해 쉽게 예측할 수 있습니다.
따라서, 선수를 스카웃하거나 트레이드할 때 선구안이 좋은 선수를 영입하면 실패할 확률이 적습니다. 하지만, 단순히 직전 시즌의 타율이나 OPS만 보고 영입한다면, 실패할 가능성이 꽤 있을 것입니다. 흔히 말하는 "먹튀" 선수가 될 수 있습니다.
소스 코드
이 포스팅 자료를 만들기 위해 사용한 파이썬 소스 코드는 다음과 같습니다. 필요하신 분은 참고하시길 바랍니다. 참고로 삼진 비율과 볼넷 비율을 계산할 때 필요한 타석수는 타수 + 볼넷 + 몸에 맞는 공 + 희생번트 + 희생플라이 + 타격방해 + 주루방해로 구하지만, 제가 사용한 레먼 데이터베이스의 경우 타격방해와 주루방해에 관한 데이터는 제공하지 않아서 그 값들은 무시했습니다. 무시해도 괜찮은 이유는 타격방해와 주루방해는 매우 드물게 일어나기 때문입니다. 따라서, 타석수 계산에 거의 영향을 미치지 않습니다.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
|
import sqlite3
import numpy as np
from scipy import stats
import matplotlib.pyplot as plt
from matplotlib import font_manager, rc
# 한글 폰트 사용을 위해서 세팅
font_path = "C:/Windows/Fonts/ngulim.ttf"
font = font_manager.FontProperties(fname=font_path).get_name()
rc('font', family=font)
with sqlite3.connect("lahmansbaseballdb.sqlite") as con:
cur = con.cursor()
cur.execute('''
select playerID, yearID, AB, H, "2B", "3B", HR, BB, HBP, SF, SH, SO from batting where yearID >= 1990 and AB >= 250 order by playerID;
''')
# playerID: 선수
# yearID: 년도
# AB: 타수
# H: 안타
# 2B: 2루타
# 3B: 3루타
# HR: 홈런
# BB: 볼넷
# HBP: 몸에 맞는 공
# SF: 희생플라이
# SH: 희생번트
# SO: 삼진
data = cur.fetchall()
player = []
year = np.zeros((len(data)))
AB = np.zeros((len(data)))
H = np.zeros((len(data)))
H2 = np.zeros((len(data)))
H3 = np.zeros((len(data)))
HR = np.zeros((len(data)))
BB = np.zeros((len(data)))
HBP = np.zeros((len(data)))
SF = np.zeros((len(data)))
SH = np.zeros((len(data)))
SO = np.zeros((len(data)))
for i in range(len(data)):
player.append(data[i][0])
year[i] = data[i][1]
AB[i] = data[i][2]
H[i] = data[i][3]
H2[i] = data[i][4]
H3[i] = data[i][5]
HR[i] = data[i][6]
BB[i] = data[i][7]
HBP[i] = data[i][8]
SF[i] = data[i][9]
SH[i] = data[i][10]
SO[i] = data[i][11]
AVG = H / AB # 타율
OBP = (H + BB + HBP) / (AB + BB + HBP + SF) # 출루율
H1 = H - H2 - H3 - HR # 1루타 갯수
SLG = (H1 + H2*2 + H3*3 + HR*4) / AB # 장타율
OPS = OBP + SLG # OPS (출루율 + 장타율)
PA = AB + BB + HBP + SH + SF # PA 타석수 (타수 + 볼넷 + 몸에 맞는 공 + 희생번트 + 희생플라이 + 타격방해 + 주루방해) 타격방해와 주루방해 데이터는 없어서 무시했음.
KPA = SO/PA # 타석당 삼진 비율 K%
BBPA = BB/PA # 타석당 볼넷 비율 BB%
beforeAVG = []
afterAVG = []
for i in range(len(data) - 1):
if data[i + 1][0] == data[i][0]:
if data[i + 1][1] == data[i][1] + 1:
beforeAVG.append(AVG[i])
afterAVG.append(AVG[i + 1])
beforeOPS = []
afterOPS = []
for i in range(len(data)-1):
if data[i+1][0] == data[i][0]:
if data[i+1][1] == data[i][1] + 1:
beforeOPS.append(OPS[i])
afterOPS.append(OPS[i+1])
beforeKPA = []
afterKPA = []
for i in range(len(data)-1):
if data[i+1][0] == data[i][0]:
if data[i+1][1] == data[i][1] + 1:
beforeKPA.append(KPA[i])
afterKPA.append(KPA[i+1])
beforeBBPA = []
afterBBPA = []
for i in range(len(data) - 1):
if data[i + 1][0] == data[i][0]:
if data[i + 1][1] == data[i][1] + 1:
beforeBBPA.append(BBPA[i])
afterBBPA.append(BBPA[i + 1])
plcc1 = round(stats.pearsonr(beforeAVG, afterAVG)[0], 4)
plcc2 = round(stats.pearsonr(beforeOPS, afterOPS)[0], 4)
plcc3 = round(stats.pearsonr(beforeKPA, afterKPA)[0], 4)
plcc4 = round(stats.pearsonr(beforeBBPA, afterBBPA)[0], 4)
plt.scatter(beforeAVG, afterAVG, c='b', s=10, alpha=0.3)
plt.title('연속된 두 시즌 동안 기록한 타율 사이의 상관관계')
plt.xlabel('특정 시즌 타율')
plt.ylabel('그 다음 시즌 타율')
plt.text(0.3, 0.2, "상관계수: " + str(plcc1), fontsize=20, color='red')
plt.grid(True)
plt.savefig('./autocorrelation_avg.png')
plt.show()
plt.scatter(beforeOPS, afterOPS, c='b', s=10, alpha=0.3)
plt.title('연속된 두 시즌 동안 기록한 OPS 사이의 상관관계')
plt.xlabel('특정 시즌 OPS')
plt.ylabel('그 다음 시즌 OPS')
plt.text(1, 0.6, "상관계수: " + str(plcc2), fontsize=20, color='red')
plt.grid(True)
plt.savefig('./autocorrelation_ops.png')
plt.show()
plt.scatter(beforeKPA, afterKPA, c='b', s=10, alpha=0.3)
plt.title('연속된 두 시즌 동안 기록한 삼진 비율 사이의 상관관계')
plt.xlabel('특정 시즌 삼진 비율')
plt.ylabel('그 다음 시즌 삼진 비율')
plt.text(0.2, 0.05, "상관계수: " + str(plcc3), fontsize=20, color='red')
plt.grid(True)
plt.savefig('./autocorrelation_kpa.png')
plt.show()
plt.scatter(beforeBBPA, afterBBPA, c='b', s=10, alpha=0.3)
plt.title('연속된 두 시즌 동안 기록한 볼넷 비율 사이의 상관관계')
plt.xlabel('특정 시즌 볼넷 비율')
plt.ylabel('그 다음 시즌 볼넷 비율')
plt.text(0.2, 0.05, "상관계수: " + str(plcc4), fontsize=20, color='red')
plt.grid(True)
plt.savefig('./autocorrelation_bbpa.png')
plt.show()
|
cs |
bskyvision의 추천글
☞ [세이버메트릭스] 타율, 출루율, OPS, RC 중 무엇이 가장 득점 생산과 연관 있을까?
☞ [세이버메트릭스] 타율이 높은 팀 vs OPS가 높은 팀, 누가 이길까?
참고자료
[1] 벤저민 바우머, 앤드루 짐발리스트 지음, "세이버메트릭스 레볼루션"
[2] blog.ncsoft.com/%EC%95%BC%EA%B5%AC-%EB%8D%B0%EC%9D%B4%ED%84%B0-%EB%B6%84%EC%84%9D-12-%EC%95%BC%EA%B5%AC-%EC%A7%80%ED%91%9C-%EA%B3%84%EC%82%B0%EB%B2%95-%ED%83%80%EC%84%9D-%EB%8B%A8%EC%9C%84-%EB%B9%84%EC%9C%A8/, ncsoft, "야구 데이터 분석 #12 야구 지표 계산법 (타석 단위 비율 지표 편)"
'Research > 야구' 카테고리의 다른 글
| [세이버메트릭스] 보살과 자살(척살)의 차이, 그리고 수비율 (5) | 2021.03.24 |
|---|---|
| [세이버메트릭스] 수비 요소를 배제하고 투수의 실력을 평가해보자, DIPS와 FIP (2) | 2021.03.11 |
| [세이버메트릭스] 타석에서 나올 수 있는 결과 중 타자와 투수의 실력의 영향을 많이 받는 것은? 반면 운에 영향을 많이 받는 것은? (0) | 2021.03.11 |
| [세이버메트릭스] 인플레이 타구가 안타가 될 확률, BABIP (10) | 2021.03.10 |
| [세이버메트릭스] 타율, 출루율, OPS, RC 중 무엇이 가장 득점 생산과 연관 있을까? (2) | 2021.03.06 |
| [세이버메트릭스] MLB에서 2019까지 1000안타 이상 친 선수 중, 홈런을 2루타보다 더 많이 쳐낸 선수는? (sqlite3) (12) | 2021.03.05 |
| [세이버메트릭스] 작년 KBO에서는 평균 연봉이 더 높은 구단이 더 잘했을까? (2019년, 2020년 분석) (6) | 2021.03.04 |
| [세이버메트릭스] 득실점 비율을 알면 실제 승률을 예측할 수 있다고? (3) | 2021.03.03 |