오늘은 SQL의 GROUP BY와 비슷한 역할을 하는 판다스 데이터프레임의 groupby() 메소드에 대해 알아보도록 하겠습니다. SQL에서 GROUP BY는 집계 함수(평균, 최대값, 최소값 등)와 함께 사용되는 것처럼 판다스 데이터프레임의 groupby() 메소드도 mean(), max() 등의 메소드와 자주 같이 사용됩니다.
데이터프레임 groupby() 메소드 사용법
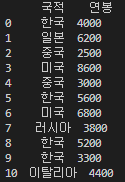
백문이 불여일견이라고 간단한 예제를 통해 groupby() 메소드의 사용법을 살펴보도록 하겠습니다. 다음과 같이 여러 사람의 국적과 연봉을 담고 있는 데이터프레임이 있다고 가정하겠습니다.
import pandas as pd
dict_data = {'국적':['한국', '일본', '중국', '미국', '중국', '한국', '미국', '러시아', '한국', '한국', '이탈리아'],
'연봉':[4000, 6200, 2500, 8600, 3000, 5600, 6800, 3800, 5200, 3300, 4400]}
df = pd.DataFrame(dict_data)
print(df)
국적을 기준으로 그룹을 지어서 국적별 연봉 평균을 알아보도록 하겠습니다.
print(df.groupby(['국적']).mean())

이와 같이 groupby()와 그룹 객체의 mean() 메소드를 활용해서 간단히 국적별 평균 연봉을 구할 수 있습니다. 제대로 계산된 건지 확인해볼까요? 국적이 한국인 사람이 총 4명이고, 각각 4000, 5600, 5200, 3300의 연봉이므로 모두 더해서 4로 나눠보니 4525가 맞네요.
이번에는 국적별 최대 연봉자의 연봉을 알아볼까요? max() 메소드를 활용하면 되겠죠?
print(df.groupby(['국적']).max())

그룹 객체 agg() 메소드 사용법
데이터프레임을 groupby() 메소드로 그룹을 지으면, 데이터프레임이 아닌 다른 객체가 됩니다. 그 객체의 클래스는 다음과 같습니다.
print(type(df.groupby(['국적'])))

저는 이 클래스의 객체들을 편의상 그룹 객체라고 하겠습니다. 만약, 한번에 국적별 연봉 평균과 최대값을 구하려면 그룹 객체의 agg() 메소드를 사용하면 됩니다. agg() 메소드에 리스트의 형태로 구하고자 하는 기초통계량과 관련된 메소드명을 넣어주시면 됩니다.
print(df.groupby(['국적']).agg(['mean', 'max']))
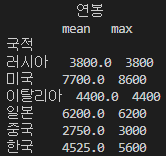
한번에 각 그룹별로 연봉의 평균과 최대값이 잘 계산된 것을 확인하실 수 있습니다.
관련 글
- [MariaDB] Group by로 그룹화된 그룹의 개수
(이 글은 마지막으로 2022년 9월 28일에 수정되었습니다)
'Dev > python' 카테고리의 다른 글
| [pandas] 튜플의 리스트를 데이터프레임으로 만들기 (0) | 2022.05.30 |
|---|---|
| [python+pandas] 데이터프레임의 기술 통계 정보(평균, 표준편차, 최대값, 최소값, 분위수)를 요약해주는 describe() 메소드 (0) | 2022.05.29 |
| [python+pandas] 여러 데이터프레임 하나의 엑셀 파일 내 각각 다른 시트에 저장하기 (5) | 2022.05.15 |
| [python] seaborn 라이브러리가 제공하는 타이타닉 데이터셋 설명 (0) | 2022.05.15 |
| [python+pandas] 판다스 데이터 프레임에서 컬럼의 고유값을 알고 싶으면, unique 메소드 (0) | 2022.04.27 |
| [pandas] 특정 컬럼 값 기준으로 데이터프레임 정렬하기, sort_values 메소드 (0) | 2022.04.26 |
| [pandas] 판다스 데이터프레임 loc, at, iloc, iat 메소드 비교 (0) | 2022.04.24 |
| [python] 파이썬 리스트에 최대 몇 개의 요소가 들어갈 수 있을까? (10) | 2022.04.19 |