SQL에서 어떤 컬럼의 값을 기준으로 데이터를 정렬해줄 때 사용되는 예약어는 ORDER BY입니다. 파이썬 판다스 데이터프레임에서 이것과 비슷한 역할을 해주는 것이 바로 sort_values 메소드입니다.
설명을 위해 간단한 데이터프레임을 하나 만들겠습니다. A, B, C, D, E, F, G라는 학생들의 수학, 영어, 역사 점수를 담은 데이터프레임입니다.
import pandas as pd
df = pd.DataFrame([[95, 92, 88], [84, 67, 88], [91, 99, 68], [87, 79, 81], [77, 92, 85], [81, 82, 83], [91, 73, 41]],
index=['A', 'B', 'C', 'D', 'E', 'F', 'G'],
columns=['math', 'english', 'history'],
)
print(df)

하나의 컬럼 기준으로 정렬
수학 점수를 기준으로 오름차순 정렬을 해보도록 하겠습니다.
print(df.sort_values(by=['math']))

수학점수가 가장 낮았던 E 학생부터 가장 높았던 A 학생 순으로 정렬되었습니다.
이번에는 수학 점수가 높은 학생부터 정렬을 해보도록 하겠습니다. 내림차순 정렬이 되어야 하므로, ascending 파라미터를 추가하면서 값은 False로 지정해줍니다.
print(df.sort_values(by=['math'], ascending=False))
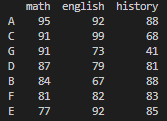
기대한 것처럼 수학점수가 가장 높았던 A학생부터 정렬되었습니다.
여러 개 컬럼 기준으로 정렬
이번에는 수학 점수가 높으면서 역사 점수가 낮은 학생부터 정렬해보도록 하겠습니다. 이 경우에는 수학 점수는 내림차순이 되어야하고, 역사 점수는 오름차순이 되어야 합니다.
print(df.sort_values(by=['math', 'history'], ascending=[False, True]))

일단 수학점수는 내림차순으로 잘 정렬된 것을 한 눈에 확인할 수 있습니다. 그리고 수학 점수 91점으로 같은 G 학생과 C 학생을 보면 영어 점수는 오름차순으로 정렬된 것을 알 수 있습니다.
정리하며
판다스의 데이터프레임만 해도 굉장히 많은 메소드들이 있기 때문에 이 모두를 암기하는 것은 불가능합니다. 중요한 것은 키워드를 기억하고 있는 것입니다. 판다스, 데이터프레임, 정렬 이 정도의 키워드를 기억해두었다가 구글에서 검색하면 필요한 메소드와 그 사용 방법을 어렵지 않게 찾을 수 있습니다. 모든 것을 외우려고 하지 마십시오. 인터넷이라는 하드디스크 상에 저장 되어 있는 내용이니, 그것을 빠르게 찾아낼 수 있는 능력만 있으면 됩니다. 단, 업무에 자주 사용하게 되는 메소드에 한해서만 뇌에 저장해 두십시오.
관련 글
- [MariaDB] Order by, 여러 개로 정렬하기 (더 중요한 것을 앞에)
- [sqlite3] 데이터 오름차순 및 내림차순으로 정렬하기.
참고자료
[1] https://pandas.pydata.org/docs/reference/api/pandas.DataFrame.sort_values.html
'Dev > python' 카테고리의 다른 글
| [python+pandas] 여러 데이터프레임 하나의 엑셀 파일 내 각각 다른 시트에 저장하기 (5) | 2022.05.15 |
|---|---|
| [python] seaborn 라이브러리가 제공하는 타이타닉 데이터셋 설명 (0) | 2022.05.15 |
| [pandas] 데이터프레임 groupby(), agg() 메소드로 그룹의 평균값, 최대값 산출하기 (0) | 2022.04.28 |
| [python+pandas] 판다스 데이터 프레임에서 컬럼의 고유값을 알고 싶으면, unique 메소드 (0) | 2022.04.27 |
| [pandas] 판다스 데이터프레임 loc, at, iloc, iat 메소드 비교 (0) | 2022.04.24 |
| [python] 파이썬 리스트에 최대 몇 개의 요소가 들어갈 수 있을까? (10) | 2022.04.19 |
| [python] UnicodeDecodeError: 'cp949' codec can't decode byte 0xed in position 135: illegal multibyte sequence 에러 해결법 (0) | 2022.04.18 |
| [python+opencv] ip 카메라(cctv)로부터 영상 받기 (2) | 2022.03.31 |