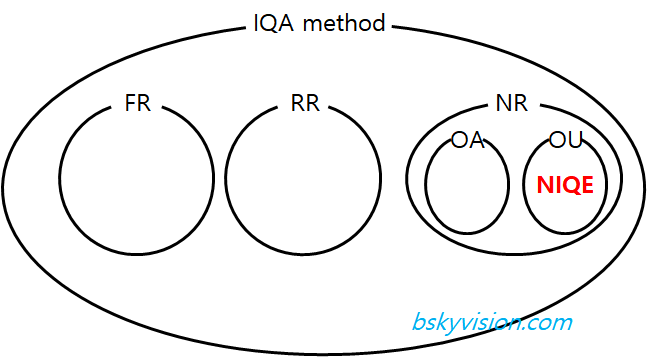
기본적으로 이미지품질평가(image quality assessment, IQA) 방법은 FR(full-reference), RR(reduced-reference), NR(no-reference)로 나눕니다. FR의 경우 이미지의 품질을 평가하기 위해 그 이미지의 깨끗한(pristine) 원본 이미지를 필요로 하는 것을 의미하고, RR의 경우는 원본 이미지의 일부 정보를 필요로 하는 것을 의미합니다. 반면 NR은 원본 이미지를 참조하는 것 없이 품질평가가 가능한 방법을 의미합니다.
NR 방식의 IQA 메소드들은 보통 훈련(training)을 필요로 합니다. 훈련이 필요하다는 뜻은 라벨(label) 값에 모델이 맞춰진다는 뜻입니다. 그래서 제대로 된 모델을 얻기 위해서는 라벨이 굉장히 중요합니다. 그런데 IQA 분야의 경우 이미지 분류, 물체 검출 이런 분야와 다르게 이 라벨이 굉장히 불안정합니다. 무슨 말이냐면, 이미지 분류의 경우 강아지 사진은 강아지고, 고양이 사진은 고양이 이렇게, 어떤 이미지에 대해 라벨링을 하는데 있어 왈가왈부할 문제가 없이 깔끔합니다. 그런데 IQA의 경우는 라벨이 주관적인(subjective) 평가에 의해 붙여집니다. 사람마다 이미지를 보고 느끼는 품질이 다르기 때문에, 여러 명이 주관적으로 품질 점수를 매긴 것을 평균내는 식으로 라벨을 얻습니다. 그러다보니 다른 그룹의 사람들에게 다시 라벨을 붙이라고 하면 달라집니다. 이처럼 IQA에 사용되는 라벨은 불안정한 편입니다.
아무튼 이처럼 라벨이 불안정하기 때문에 여기에 맞춰 훈련되는 NR 방식의 모델도 일반화된 성능을 갖기가 어렵습니다. 그러다보니 A 데이터셋에서는 잘 작동되던 모델이 B 데이터셋에서는 잘 작동하지 않는 경우가 허다합니다.
그렇기 때문에 가장 이상적인 것은 라벨에 모델을 맞추는 훈련 과정이 필요없는 모델을 개발하는 것입니다. 오늘 소개하고자 하는 NIQE는 그것을 추구한 모델입니다. 그러한 모델들을 NIQE의 저자들은 OU(opinion unaware) 방식이라고 불렀습니다. 또한 그와 대조되는 방식은 OA(opinion-aware)라고 명시했습니다. 대부분의 NR IQA 모델들은 OA 방식에 속합니다.
그러면 OU 방식이 라벨로부터 자유로워서 좋다는 장점이 있다는 것은 알겠는데, 문제는 그것을 어떻게 실현시키느냐겠죠. 이제 NIQE의 저자들이 어떻게 그것을 실현시켰는지에 대해 살펴보도록 하겠습니다. 참고로 NIQE의 original 논문은 2012년에 IEEE Signal Processing Letters에 게재된 "Making a 'completely blind' image quality analyzer"입니다. 저자는 BRISQUE를 만든 LIVE 연구실의 Mittal 등입니다.
NIQE의 기본적 작동원리를 한문장으로 정리하자면 다음과 같습니다. "깨끗한 이미지들이 평균적으로 어떤 특성을 갖는지 살펴본 후, 그것을 테스트 이미지의 특성과 비교해서, 둘이 비슷할수록 테스트 이미지의 품질이 좋은 것으로 합시다."
자, 그럼 이제 구체적으로 한단계 한단계 살펴보겠습니다. 먼저 NIQE의 저자들은 125개의 왜곡 없는 깨끗한 이미지를 준비했습니다.
언뜻 봐도 상당히 고퀄리티의 이미지들이죠? 그 다음에 이 깨끗한 이미지들 속에 숨겨져 있는 통계적 특성을 도드라지게 하기 위해서 각 이미지들에 MSCN 전처리를 해줍니다. 결과적으로 MSCN 처리된 이미지의 픽셀들의 히스토그램을 살펴보면 모두 가우시안 분포를 따릅니다. MSCN과 BRISQUE 를 설명할 때 했던 이야기들입니다. 그 다음에 이미지들을 P x P 사이즈의 패치로 분할해줍니다. 그 패치들 중에 어떤 패치들은 촬영당시 아웃포커스 효과로 인해 블러된 패치들이 있을 수도 있기 때문에 패치의 sharpness가 일정 정도 이상되는 패치만 남겨둡니다. 다음과 같이 말이죠.

이런 방식으로 125개 이미지마다 몇 개의 패치들이 선택되는데, 선택된 총 패치의 수를 저는 $N_1$이라고 하겠습니다. 그 다음에 각 패치들에서 BRISQUE에서 사용한 것과 동일한 36개의 특성을 도출해줍니다. 그러면 $N_1$개의 36개 벡터가 생성되겠죠. 이 벡터들의 평균 벡터(mean vector) $\nu_1$와 공분산 행렬(covariance matrix) $\Sigma_1$을 계산합니다. 이 $\nu_1$과 $\Sigma_1$이 깨끗한 이미지의 품질을 대표한다고 볼 수 있습니다. 우리는 지금까지 깨끗한 이미지들이 평균적으로 어떤 특성을 갖는지를 살펴봤습니다.
이제 테스트할 하나의 이미지가 어떤 특성을 갖는지를 살펴볼 차례입니다. 동일하게 먼저 테스트 이미지에 MSCN 전처리를 해줍니다. 그리고 P x P 사이즈의 패치로 분할해줍니다. 테스트 이미지의 경우 sharpness에 따라 thresholding 해주는 단계를 거치지 않고 모든 패치를 다 사용합니다. 왜냐하면 테스트 이미지의 경우 아웃포커스 효과가 품질에 좋은 영향을 미치는지 나쁜 영향을 미치는지 섣불리 판단해서는 안되기 때문입니다. 테스트 이미지에서 나온 패치의 수를 저는 $N_2$라고 하겠습니다. 각 패치에서 역시 36개의 BRISQUE 특성을 도출합니다. 그러면 $N_2$개의 36개 벡터가 생성될 것입니다. 이 벡터들의 평균 벡터 $\nu_2$와 공분산 행렬 $\Sigma_2$을 계산해줍니다. 이것들이 테스트 이미지의 품질을 대표한다고 볼 수 있습니다.
이제 마지막으로 깨끗한 이미지의 품질을 대표하는 $\nu_1$, $\Sigma_1$과 테스트 이미지의 품질을 대표하는 $\nu_2$, $\Sigma_2$의 유사도를 계산해서 테스트 이미지의 품질을 예측합니다. 유사도 또는 거리를 계산한다고 생각하시면 됩니다. 다음과 같은 공식으로 그 유사도 또는 거리를 구할 수 있습니다.

거리가 짧을 수록 깨끗한 이미지와 통계적 특성이 비슷한 것이므로 품질이 좋은 것이고, 거리가 멀 수록 통계적 특성이 비슷하지 않은 것이므로 품질이 나쁜 것입니다. 이것이 바로 NIQE가 테스트 이미지의 품질을 예측하는 방식입니다. 이런 방식으로 NIQE는 사람이 매긴 라벨에 모델을 맞추는 훈련 과정에서 자유로운 모델이 되었습니다.
참고로 NIQE의 original 논문에서는 평균벡터와 공분산행렬을 구한 것을 다변량 가우시안(multivariate Gaussian) 분포의 확률밀도함수를 찾아낸 것으로 해석했습니다. 정규분포를 따르는 확률변수의 평균과 분산을 알면 확률밀도함수를 구할 수 있기 때문입니다.
NIQE에 대한 설명은 여기까집니다. 논문에서 난해하다고 느껴질 수 있는 부분들은 제가 이해한 방식으로 최대한 풀어서 설명했습니다. NIQE도 IQA에서 꽤 중요한 논문이니 작동원리를 잘 이해하셨으면 좋겠습니다. 질문과 지적 및 토론은 항상 환영이니 댓글 남겨주세요.^^
bskyvision의 추천글 ☞
경험 품질에 관한 레이블, MOS(mean opinion score)와 DMOS(differential opinion score)
다변량 정규분포의 확률밀도함수 (MATLAB 소스코드 포함)
<참고자료>
'Research > 컴퓨터비전, 영상처리' 카테고리의 다른 글
| [IQA] NSS 특성과 CNN으로 얻은 특성을 함께 조합해서 이미지 품질 평가에 활용한 NR IQA 방법 (0) | 2020.08.03 |
|---|---|
| 얼굴 랜드마크(facial landmark)란? (0) | 2020.08.01 |
| 머리 자세 추정(head pose estimation)에서 pitch, roll, yaw angle이란? (1) | 2020.07.31 |
| 동적 텍스처(dynamic texture) 분류란? (0) | 2020.06.29 |
| [IQA] 이미지품질평가 분야의 셀럽, BRISQUE (9) | 2020.06.03 |
| 선형보간법(linear interpolation)과 삼차보간법(cubic interpolation), 제대로 이해하자 (15) | 2020.05.29 |
| 지각(perception)과 인지(cognition)의 차이 이해하기 (25) | 2020.05.26 |
| 최소식별차(just-noticeable-difference)와 영상압축 (2) | 2020.05.25 |