반응형
pandas 데이터프레임 내 중복 데이터(중복 행)를 제거할 때는 drop_duplicates() 메소드를 사용합니다.
drop_duplicate() 메소드로 중복 행 제거하기
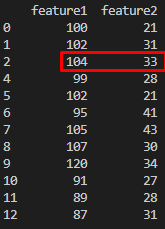
다음과 같은 엑셀 파일이 있다고 가정하겠습니다.

보시다시피 3번째 행과 4번째 행은 같은 값들을 갖고 있습니다. 이런 경우에 drop_duplicates() 메소드를 사용하면 두번째로 출현한 4번째 행이 제거됩니다.
import pandas as pd
df = pd.read_excel('./dataset1.xlsx')
print(df)
df1 = df.drop_duplicates()
print(df1)
만약 특정 컬럼 기준으로 중복 데이터를 제거하고 싶으면 다음과 같이 컬럼명을 리스트 안에 넣어서 인수로 전달해주면 됩니다.
df = df.drop_duplicates(["features2"])
참고자료
'Dev > python' 카테고리의 다른 글
| [pandas] 파이썬 판다스로 엑셀 파일을 읽고 쓰려면 openpyxl도 추가로 설치해야 함 (0) | 2022.08.15 |
|---|---|
| [flask+jinja2] flask 프로젝트에서 html에 이미지 삽입하는 방법 (0) | 2022.08.09 |
| [PyQt6] pyqt 앱 윈도우 크기 고정 방법 (0) | 2022.08.05 |
| [python] playsound 라이브러리 playsound.PlaysoundException: Error 259 for command 예외 해결 방법 (2) | 2022.08.04 |
| [pandas] 누락된 데이터가 - 등의 기호로 표현되어 있을 때 NaN으로 변경하는 방법, replace() 메소드 (0) | 2022.07.29 |
| [python] powershell에서 virtualenv 가상환경 활성화시 발생하는 오류 해결 방법 (0) | 2022.07.27 |
| [python] ModuleNotFoundError: No module named 'PIL' 오류 해결 방법 (0) | 2022.07.26 |
| [pandas] 특정 날짜 이후 데이터만 선택하기 (0) | 2022.07.26 |