판다스 데이터프레임에서 NaN 값이 있는 행 또는 열을 삭제할 때는 dropna() 메소드를 사용할 수 있습니다. NaN 값을 포함하고 있는 planets 데이터셋을 선택하여 dropna() 메소드를 사용했을 때의 결과를 보여드리도록 하겠습니다.
planets 데이터셋은 seaborn에서 제공합니다. 행성에 관한 정보를 담고 있습니다. info() 메소드로 컬럼별로 몇 개의 NaN이 아닌 데이터가 들어 있는지 확인해보겠습니다.
import seaborn as sns
import pandas as pd
dataset = sns.load_dataset('planets')
print(dataset.info())

총 1305개의 행과 6개의 컬럼으로 이뤄진 데이터셋이고, method, number, year 컬럼은 결측치가 없습니다. 반면 orbital_period, mass, distance 컬럼은 결측치가 있는 상황입니다.
dropna() 메소드 사용법
dropna() 메소드로 결측치 있는 행 모두 제거하기
dropna() 메소드로 결측치가 하나라도 있는 행들을 제거해보도록 하겠습니다. 이를 위한 dropna() 메소드의 사용법은 다음과 같습니다.
데이터프레임.dropna()
# 또는
데이터프레임.dropna(axis=0)
코드는 다음과 같습니다.
import seaborn as sns
import pandas as pd
dataset = sns.load_dataset('planets')
print(dataset.info())
dataset_NaN_deleted = dataset.dropna()
print(dataset_NaN_deleted.info())
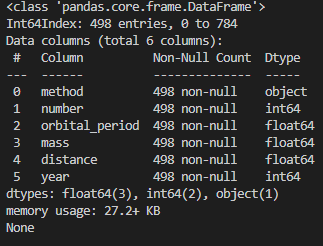
NaN이 하나라도 있는 행을 제거했더니 498개의 행만 살아남은 것을 확인하실 수 있습니다. 특성 6개가 온전히 다 있는 행은 498개 행 뿐이었던 것입니다.
dropna() 메소드로 결측치 있는 열 모두 제거하기
이번에는 NaN 값이 있는 컬럼을 모두 제거해보겠습니다. NaN 값을 포함하고 있는 컬럼들인 orbital_period, mass, distance이 제거되면 되겠죠? 사용법은 다음과 같습니다. 이번에는 dropna() 메소드의 매개변수 axis가 1이 되어야 합니다. axis 1이 컬럼인지 행인지 헷갈리시는 분들은 1이니까 수직 이렇게 외우시기 바랍니다.
데이터프레임.dropna(axis=1)
import seaborn as sns
import pandas as pd
dataset = sns.load_dataset('planets')
print(dataset.info())
dataset_NaN_deleted = dataset.dropna(axis=1)
print(dataset_NaN_deleted.info())
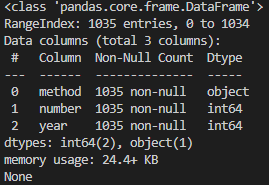
예상했듯이 3개의 컬럼만 살아남고 나머지 컬럼은 모두 제거된 것을 확인할 수 있습니다.
특정 컬럼 값에 결측치가 있는 행 제거하기
이번에는 특정 컬럼 값에 결측치가 있는 행을 제거하는 방법을 살펴보겠습니다. orbital_period 컬럼의 값이 NaN인 행들을 제거해보겠습니다.
import seaborn as sns
import pandas as pd
dataset = sns.load_dataset('planets')
print(dataset.info())
dataset_NaN_deleted = dataset.dropna(subset=['orbital_period'], how='any', axis=0)
print(dataset_NaN_deleted.info())
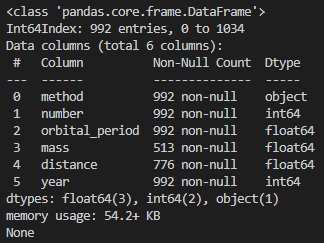
보시는 것처럼 orbital_period 컬럼 값이 NaN이었던 행들이 제거되면서 992개 행이 남았습니다.
결측치가 있는 경우 행과 열 중에 어떤 것을 삭제하는 것이 나은가?
데이터에 결측치가 있는 경우에 어떤 알고리즘을 훈련시키려면 결측치가 있는 행이나 열을 제거해야 합니다.
1) 샘플의 개수를 많이 남기려면, NaN이 있는 열을 제거하는 것이 낫습니다. 샘플의 개수는 유지되지만, 특성 개수는 줄어들 것입니다.
2) 특성의 개수를 많이 남기려면, NaN이 있는 행을 제거하는 것이 낫습니다. 특성의 개수는 유지되지만, 샘플 개수는 줄어들 것입니다.
정리하며
저는 python 3.9.5, pandas 1.3.3 환경에서 실습을 진행하였습니다. 혹시 버전이 다른 경우에 일부 코드가 제대로 실행되지 않을 수도 있습니다.
관련 글
- [pandas] 각 컬럼 데이터 중 NaN이 아닌 데이터의 개수를 보여주는 info() 메소드
'Dev > python' 카테고리의 다른 글
| [pandas] 특정 날짜 이후 데이터만 선택하기 (0) | 2022.07.26 |
|---|---|
| [PySide6] QLabel 수평 가운데에 배치하기 (0) | 2022.07.23 |
| [pandas] 결측치를 다른 값으로 채워 넣는 방법, fillna 메소드 (0) | 2022.07.23 |
| [PySide6] QLineEdit 위젯에 placeholder 넣는 방법 (0) | 2022.07.22 |
| [python] selenium 크롤링 find_element_by_css_selector 더 이상 사용 불가 (0) | 2022.07.21 |
| [python] SQLAlchemy, MySQL 연결 에러 해결 방법(pool_recycle 수정?) (0) | 2022.07.20 |
| [pandas] 데이터프레임 컬럼 내 고유값의 개수 구하기, value_counts() 메소드 (0) | 2022.07.19 |
| [pandas] 각 컬럼 데이터 중 NaN이 아닌 데이터의 개수를 보여주는 info() 메소드 (0) | 2022.07.18 |