요즘 semantic segmentation을 활용하는 연구를 하나 진행하고 있다. semantic segmentation, 이름만 봐서는 이것이 무엇인지 감이 안오는 분들이 있을 것이다. 구지 번역하자면 '의미적 분할' 정도로 번역이 가능할 것 같다. 간단히 이야기해서 이미지를 의미있게 분할하는 것이 바로 semantic segmentation이다. 이 글을 차근히 읽어나가면 확실하게 알 수 있을 것이다. 인내하고 끝까지 읽는 자에게 복이 있나니...^^
오늘 이 글에서는 semantic segmentation의 목적이 무엇인지, 어디에 적용될 수 있는지, 그리고 대표적인 알고리즘인 FCN(fully convolutional networks)의 원리는 무엇인지에 대해서 소개하려고 한다.
Semantic segmentation의 목적
semantic segmentation은 이미지 내에 있는 물체들을 의미 있는 단위로 분할해내는 것이다. 좀 더 구체적으로 이야기하면, 이미지의 각 픽셀이 어느 클래스에 속하는지 예측하는 것이다. 이렇게 이미지 내 모든 픽셀에 대해서 예측을 진행하기 때문에 이 과제를 dense prediction이라고 부르기도 한다. 어떤 이미지 내에는 사람, 자동차, 강아지, 고양이, 노트북, 선풍기 등 여러 종류의 물체가 포함되어 있을 수 있다. 이렇게 서로 다른 종류의 물체들을 깔끔하게 분할해내는 것이 semantic segmentation의 목적이다.

사람의 눈으로 이미지를 의미에 따라 분할해내는 것은 결코 어렵지 않은 일이다. 하지만 이것을 컴퓨터, 기계에게 하라고 하면 결코 쉽지 않은 작업이다. 불과 몇년 전까지만 해도 사실상 거의 불가능했다. 딥러닝이 발전하기 전까지만 해도 말이다. 그러나 딥러닝의 한 알고리즘인 컨볼루션 신경망(Convolutional neural network, CNN)이 등장하면서 엄청난 발전을 이뤘다. 잘 훈련된 semantic segmentation 알고리즘은 사람과 비슷한 수준으로 semantic segmentation을 수행한다. 물론 알고리즘을 훈련시키기 위해서는 수만장의 이미지와 그에 해당하는 픽셀 단위 ground-truth 라벨값들이 투입되어야한다.
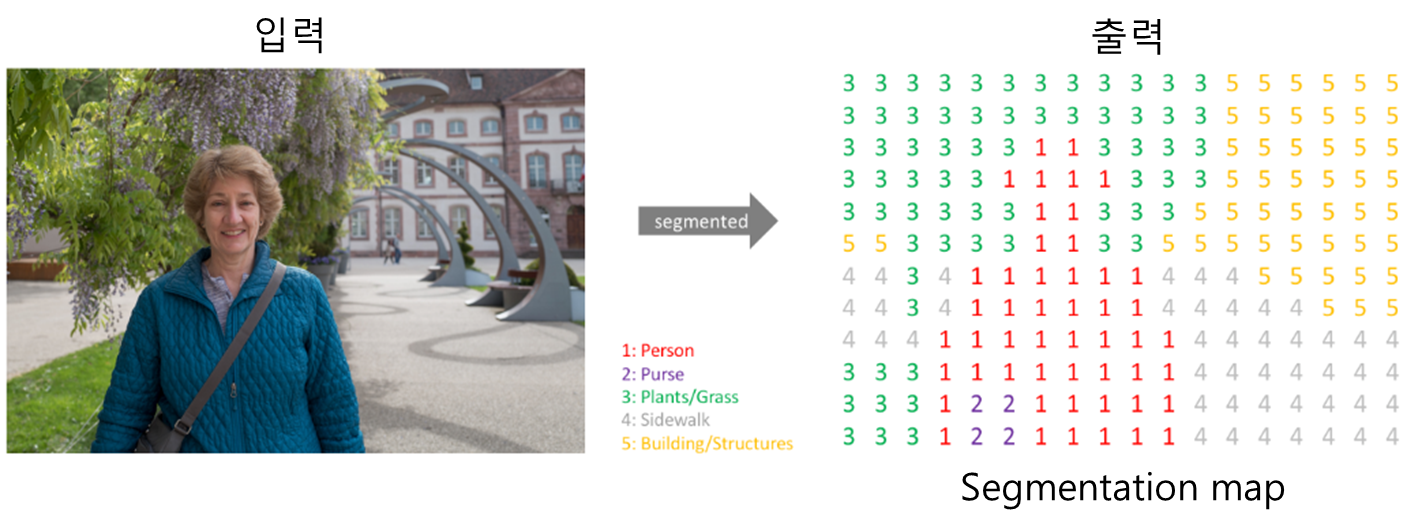
semantic segmentation을 어떤 이미지에 시행하면 다음 그림과 같이 각 픽셀이 어느 클래스에 속하는지 알게 된다. 즉, semantic segmentation 알고리즘의 입력값은 컬러 이미지 또는 흑백 이미지고, 출력값은 각 픽셀의 예측된 클래스를 나타내는 segmentation map이다. 이 segmentation map을 얻는 것이 semantic segmentation의 실질적 목적이다.
Semantic segmentation의 적용분야
semantic segmentation의 주된 적용분야 중에 하나가 바로 '자율주행자동차'다. 아래 그림을 살펴보자.

위 그림을 보면 사람, 자동차, 트램, 신호등, 표지판, 나무, 도로 등으로 이미지가 분할된 것을 확인할 수 있다. 자율주행자동차에 탑재된 카메라들로부터 촬영된 영상들에서 사람, 자동차, 신호등, 표지판, 도로 등이 어디에 있는지를 알아내야 안전하게 주행을 수행할 수 있기 때문에, semantic segmentation은 필수적인 과정이다.
또한 영상처리 및 컴퓨터비전이 그동안 의료 분야에 많이 기여해왔던 것처럼 semantic segmentation도 역시 의료 이미지 분석에 적용될 수 있다. 아래 그림을 참고하자.

흉부 X-ray 사진에 semantic segmentation을 수행했더니 심장(빨강색), 폐(연두색), 쇄골(파란색)과 같은 부분들을 잘 분할해냈다. 이와 같은 처리는 의사가 X-ray 사진을 분석하는데 도움이 될 것이다.
Semantic segmentation의 대표적 알고리즘, FCN
그렇다면 Semantic segmentation 알고리즘들은 어떤 원리로 이렇게 멋진 작업을 수행해내는 것일까? Semantic segmentation에서 가장 대표적인 모델인 FCN (fully convolutional networks)에 대해서 여기서 소개하겠다.
FCN은 버클리 대학의 Jonathan Long 등이 2015년 CVPR에 발표한 Semantic segmentation 알고리즘이다[8]. FCN의 original 논문의 제목은 "Fully convolutional networks for semantic segmentation"이다. 이후에 출시된 알고리즘들은 사실상 FCN을 개선한 아류작들이라고 볼 수 있다. 그만큼 FCN이 선두적인 역할을 했다.
AlexNet, VGGNet 등 이미지 분류(image classification)용 CNN 알고리즘들은 일반적으로 컨볼루션 층들과 fully connected 층들로 이뤄져있다. 항상 입력이미지를 네트워크에 맞는 고정된 사이즈로 작게 만들어서 입력해준다. 그러면 네트워크는 그 이미지가 속할 클래스를 예측해서 알려준다. 아래 그림에서 네트워크는 입력된 이미지의 클래스를 얼룩무늬 고양이(tabby cat)라고 예측해냈다.

이 분류용 CNN 알고리즘들은 이미지에 있는 물체가 어떤 클래스에 속하는지는 예측해낼 수 있지만, 그 물체가 어디에 존재하는지는 예측해낼 수 없다. 왜냐하면 네트워크 후반부의 fully connected 층에 들어서면서 위치정보가 소실되었기 때문이다. 따라서 AlexNet, VGGNet 등과 같은 알고리즘들을 수정함없이 Semantic segmentation 과제에 그대로 사용하는 것은 불가능하다.
FCN 개발자들은 위치정보가 소실되지 않게 하기 위해서, 또한 어떠한 크기의 입력이미지도 허용하기 위해서 다음과 같이 알고리즘을 발전시켜간다. 먼저 고정된 크기의 인풋만을 허용하는 fully connected 층을 1x1 컨볼루션층으로 바꿔준다.

결과적으로 네트워크 전체가 컨볼루션층들로 이뤄지게 되었다. fully connected 층들이 없어졌으므로 더 이상 입력 이미지의 크기에 제한을 받지 않게 되었다.

이제 어떠한 사이즈 H x W의 이미지도 이 네트워크에 입력될 수 있다. 여러 층의 컨볼루션층들을 거치고 나면 특성맵(feature map)의 크기가 H/32 x W/32가 되는데, 그 특성맵의 한 픽셀이 입력이미지의 32 x 32 크기를 대표한다. 즉, 입력이미지의 위치 정보를 '대략적으로' 유지하고 있는 것이다.
여기서 중요한 것은 이 컨볼루션층들을 거치고 나서 얻게 된 마지막 특성맵의 갯수는 훈련된 클래스의 갯수와 동일하다는 것이다. 21개의 클래스로 훈련된 네트워크라면 21개의 특성맵(이것을 heatmap이라고도 부른다)을 산출해낸다. 각 특성맵은 하나의 클래스를 대표한다. 만약 고양이 클래스에 대한 특성맵이라면 고양이가 있는 위치의 픽셀값들이 높고, 강아지 클래스에 대한 특성맵이라면 강아지 위치의 픽셀값들이 높다.

이 대략적인(coarse) 특성맵들의 크기를 원래 이미지의 크기로 다시 복원해줄 필요가 있다. 이미지의 모든 픽셀에 대해서 클래스를 예측하는 dense prediction을 해주는 것이 semantic segmentation의 목적이기 때문이다. (coarse와 dense는 서로 반의어다.) 이 원래 이미지 크기로 복원하는 과정을 upsampling이라고 부른다. upsampling을 통해 각 클래스에 해당하는 coarse한 특성맵들을 원래 사이즈로 크기를 키워준다. upsampling된 특성맵들을 종합해서 최종적인 segmentation map을 만든다. 간단히 말해서, 각 픽셀당 확률이 가장 높은 클래스를 선정해주는 것이다. 만약 (1, 1) 픽셀에 해당하는 클래스당 확률값들이 강아지 0.45, 고양이 0.94, 나무 0.02, 컴퓨터 0.05, 호랑이 0.21 이런 식이라면, 0.94로 가장 높은 확률을 산출한 고양이 클래스를 (1, 1) 픽셀의 클래스로 예측하는 것이다. 이런 식으로 모든 픽셀이 어느 클래스에 속하는지 판단한다.

그런데 단순히 upsampling을 시행하면, 특성맵의 크기는 원래 이미지 크기로 복원되고, 그것들로부터 원래 이미지 크기의 segmentation map을 얻게 되지만 여전히 coarse한, 즉 디테일하지 못한 segmentation map을 얻게 된다. 1/32만큼 줄어든 특성맵들을 단숨에 32배만큼 upsampling 했기 때문에 당연히 coarse할 수 밖에 없다. 이렇게 단숨에 32배 upsampling하는 방법을 논문에서는 FCN-32s라고 소개하고 있다. 아래 그림을 보자. ground truth와 비교해 FCN-32s로 얻은 segmentation map은 많이 뭉뚱그려져 있고 디테일하지 못함을 알 수 있다.

FCN의 개발자들은 좀더 디테일한 segmentation map을 얻기 위해 skip combining이라는 기법을 제안한다. 기본적인 생각은 다음과 같다. 컨볼루션과 풀링 단계로 이뤄진 이전 단계의 컨볼루션층들의 특성맵을 참고하여 upsampling을 해주면 좀 더 정확도를 높일 수 있지 않겠냐는 것이다. 왜냐하면 이전 컨볼루션층들의 특성맵들이 해상도 면에서는 더 낫기 때문이다. 이렇게 바로 전 컨볼루션층의 특성맵(pool4)과 현재 층의 특성맵(conv7)을 2배 upsampling한 것을 더한다. 그 다음 그것(pool + 2x conv7)을 16배 upsampling으로 얻은 특성맵들로 segmentation map을 얻는 방법을 FCN-16s라고 부른다. 아래 그림을 참고하자.

또 더 나아가서 전전 컨볼루션층의 결과도 참고해서 특성맵들을 얻고, 또 그 특성맵들로 segmentation map을 구할 수도 있다. 이 방법은 FCN-8s라고 부른다. 좀 더 구체적으로 이야기하면, 먼저 전전 단계의 특성맵(pool3)과 전 단계의 특성맵(pool4)을 2배 upsampling한 것과 현 단계의 특성맵(conv7)을 4배 upsampling 한 것을 모두 더한 다음에 8배 upsampling을 수행하므로 특성맵들을 얻는다. 이것을 모두 종합해서 최종 segmentation map을 산출한다.

아래 그림을 보면 FCN-8s가 FCN-16s보다 좀 더 세밀하고, FCN-32s보다는 훨씬 더 정교해졌음을 알 수 있다. 다른 논문에서, 또는 웹상에서 누군가 FCN을 말할 때는 보통 이 FCN-8s를 의미한다고 봐도 무방하다.

첨부1: Semantic segmentation과 Object detection의 차이
혹시나 semantic segmentation이 무엇인지 아직 헷갈릴 수도 있는 분들을 위해서 추가적으로 챕터를 준비했다. object detection과 비교해보면 semantic segmentation이 무엇을 위한 것인지 좀 더 분명하게 확인될 것이다. 바운딩 박스로 검출된 물체들을 나타내는 object detection과 다르게, semantic segmentation은 이미지 내 모든 픽셀이 각각 어느 클래스에 속하는지 예측하고 그것들을 모아서 이미지를 의미 있는 단위로 분할한다.

위 그림과 같이 object detection은 이미지 내에서 물체들을 검출한 것을 직사각형의 바운딩 박스로 묶어서 표현해내는 반면, semantic segmentation은 각자 다른 클래스에 속하는 물체들을 좀 더 정확하게 분할해낸다. 양(sheep)들은 모두 양 클래스에 속하므로 하나의 색으로 표현되었다.
첨부2: Semantic segmentation과 Instance Segmentation의 차이
semantic segmentation과 관련해서 조사를 하다보면 instance segmentation라고 불리는 것을 종종 보게 된다. semantic segmentation의 경우 같은 클래스에 속하면 각각 독립된 개체라고 하더라도 하나의 색으로 나타냈었다. 반면 instance segmentation의 경우 같은 클래스에 속하더라도 독립된 개체라면 각기 다른 색으로 표현해준다. 아래 그림에서 오른쪽 그림을 보면, 세 마리의 양들을 각기 다른 색으로 표현해준 것을 확인할 수 있다.

끝까지 읽어주셔서 대단히 감사합니다. 인내의 열매를 누리고 계실 것이라 믿으며 글을 마칩니다. 질문, 지적, 칭찬 모두 환영합니다.^^
<참고자료>
[1] https://towardsdatascience.com/detection-and-segmentation-through-convnets-47aa42de27ea, Ravindra Parmar, "Detection and Segmentation through ConvNets"
[2] https://thegradient.pub/semantic-segmentation/, The Gradient, "Going beyond the bounding box with semantic segmentation"
[3] https://medium.com/hyunjulie/1%ED%8E%B8-semantic-segmentation-%EC%B2%AB%EA%B1%B8%EC%9D%8C-4180367ec9cb, 심현주, "1편: Semantic segmentation 첫걸음!"
[4] https://www.jeremyjordan.me/semantic-segmentation/#dilated_convolutions, Jeremy Jordan, "An overview of semantic image segmentation"
[5] http://blog.naver.com/PostView.nhn?blogId=laonple&logNo=220964957738&parentCategoryNo=&categoryNo=&viewDate=&isShowPopularPosts=false&from=postView, 라온피플, "[Machine Learning Academy_part VII. Semantic Segmentation] 3. FCN [2]"
[6] https://towardsdatascience.com/review-fcn-semantic-segmentation-eb8c9b50d2d1, Sik-Ho Tsang, "Review: FCN-Fully Convolutional Network (Semantic Segmentation)"
[7] https://modulabs-biomedical.github.io/FCN, 모두의연구소, "Fully Convolutional Networks for Semantic Segmentation"
[8] Jonathan Long 등, "Fully Convolutional Networks for Semantic Segmentation", CVPR 2015 (FCN의 original 논문)
[9] https://reniew.github.io/18/, reniew's blog, "CNN을 활용한 주요 Model - (4) : Semantic Segmentation"
'Research > 컴퓨터비전, 영상처리' 카테고리의 다른 글
| 한계효용체감의 법칙이란? (7) | 2019.08.20 |
|---|---|
| [IQA] 미리 훈련된 CNN으로 얻은 특성맵들의 품질로 이미지의 품질을 평가하는 모델, DeepSim (0) | 2019.07.10 |
| [Visual saliency] 중요 물체 검출(salient object detection, SOD)이란? (2) | 2019.07.06 |
| 경험 품질에 관한 레이블, MOS(mean opinion score)와 DMOS(differential opinion score) (0) | 2019.07.05 |
| JPEG 압축 제대로 이해하기 (19) | 2019.05.09 |
| visual masking이란? (0) | 2019.05.07 |
| Bag of Words (BoW) 이해하기 (0) | 2019.04.17 |
| 이미지 라벨링 툴 labelImg 사용 중 에러 해법 (0) | 2019.04.12 |