visual saliency 알고리즘은 이전 포스팅 https://bskyvision.com/509에서 설명했듯이, 이미지 내에서 시각적으로 의미있는 지역이 어딘가를 예측해주는 알고리즘이다. 크게 두 부류로 나눌 수 있는데, 하나는 FP(fixation prediction) 방식이고 또다른 하나는 SOD(salient object detection) 방식이다. 전자는 사람의 시선이 머물 곳을 예측해내는 방식이고, 후자는 시각적으로 중요한 물체를 검출해내는 방식이다.
GBVS의 이해
GBVS(graph-based visual saliency)는 FP 방식에 속하는 알고리즘이다. 이 알고리즘의 original paper는 캘리포니아 공대의 Harel 등이 저술한 "Graph-based Visual Saliency"이다. GBVS를 개발할 때 저자들이 주안점을 둔 가설은 "시각적으로 중요한 로컬 이미지 패치는 그것과 이웃한 로컬 이미지 패치들과 상당히 다르다"이다. 그들은 마코브 체인(Markov chain) 방법을 사용해서 로컬 패치들 간의 비유사도를 측정했다.
저자들은 우수한 visual saliency 모델들은 다음과 같은 단계로 구성되어 있다고 정리했다.
1) Extraction (특성 도출): 이미지의 여러 다양한 특성을 반영하는 특성맵들을 도출한다.
2) Activation (활성화): 각 특성맵을 활성화시킨다.
3) Normalization/Combination (표준화/조합): 활성화된 특성맵들을 표준화한 후에 하나의 맵으로 조합한다.
따라서 저자들은 GBVS는 다음과 같이 작동하도록 개발했다. 먼저 세기(intensity), 방향(orientation), 컬러(color)와 같은 저차원의 특성맵들을 도출한다. (참고로 나는 지금 디폴트 세팅의 경우를 말하고 있다.) 이미지 피라미드를 이용해서 여러 스케일에서 특성맵을 도출한다. 결과적으로 24개의 특성맵(intensity 3개, orientation 12개, color 9개)이 산출된다. 그 다음에 graph 기반 활성화를 이용해서 특성맵들을 활성화시켜준다. (이때 마코브 체인 방법이 사용된다.) 이어서 fast raise to power scheme을 이용해서 특성맵을 표준화한다. (이때도 마코브 체인 방법이 사용된다.) 이제 각 채널 내의 특성맵들을 모두 더해준다. 따라서 intensity 특성맵 1개, orientation 특성맵 1개, color 특성맵 1개로 정리된다. 이 세 채널의 특성맵을 모두 더해서 saliency 맵을 산출한다. 더 좋은 성능을 위해 saliency 맵을 blur 해준다.
GBVS 내부 들여다보기
그러면 이제 실제 하나의 이미지를 GBVS가 어떻게 처리해가는가를 살펴보자. 아래 이미지를 테스트 이미지로 사용했다. 첫째 딸 로아 막 100일 지났을 때 사진이다. (귀엽죠?ㅋㅋ)

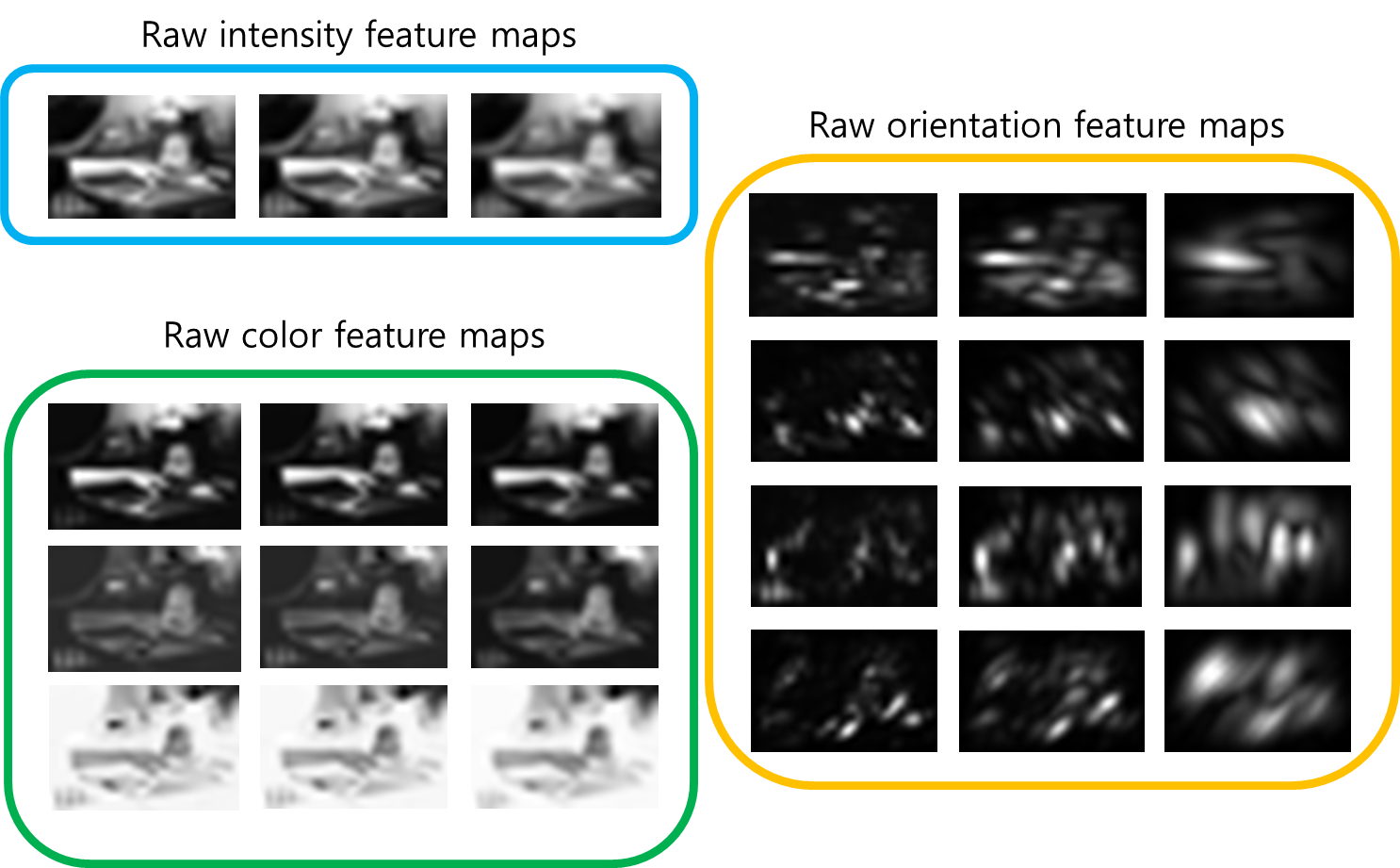
step1: compute raw feature maps from image
GBVS는 먼저 여러 개의 특성맵을 도출합니다. 위에서 언급한대로 24장의 특성맵을 도출하는데, 그 중 3개는 intensity에 관한 것이고, 12개는 orientation에 관한 것이고, 9개는 color에 관한 것이다.
step2: compute activation maps from feature maps
그 다음에는 각 특성맵들을 활성화해준다.

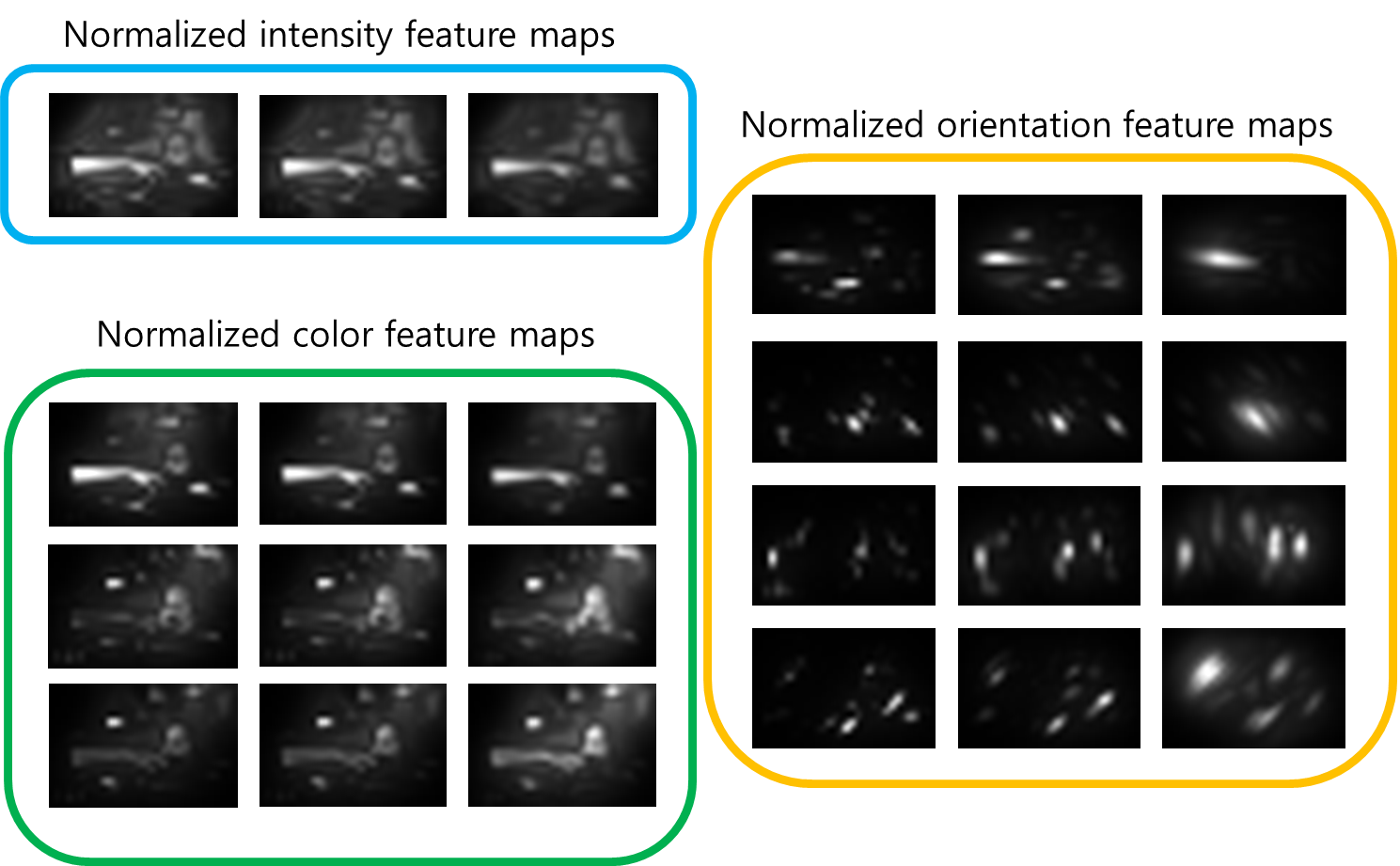
step3: normalize activation maps
이어서 활성화된 맵을 표준화해준다.
step4: sum across maps within each feature channel
각 특성 채널의 특성맵들을 더해준다. 결과적으로 3장의 특성맵으로 정리되었다.

step5: sum across feature channels
모든 채널의 특성맵들을 더해서 최종 saliency 맵을 산출해준다.

step6: blur for better results
최종 saliency 맵에 blur 효과를 줌으로써 성능을 극대화시킨다.
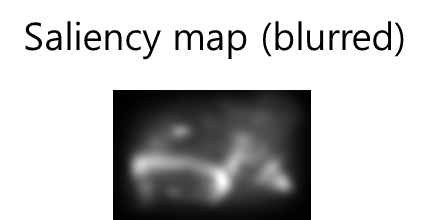
saliency 맵이 잘 산출되었는지, 위의 테스트 이미지와 비교해보자. 이미지 내에서 중요한 부분들이 어느정도 잘 강조되었음을 확인할 수 있을 것이다.
끝까지 인내심을 가지고 읽어주셔서 감사합니다. GBVS에 대해 조금이나마 이해하시는데 도움이 되었길 바라며, 글을 마칩니다.^^ GBVS의 매틀랩 코드는 [3]에서 다운로드 받으실 수 있습니다.
<참고자료>
[1] https://www.ncbi.nlm.nih.gov/pmc/articles/PMC5206280/, Veale 등, "How is visual salience computed in the brain? Insights from behaviour, neurobiology and modelling"
[2] http://www.scholarpedia.org/article/Visual_salience#Simple_computational_framework, Itti, "Visual salience"
[3] http://www.vision.caltech.edu/~harel/share/gbvs.php
[4] Wang et al., "Learning a Combined Model of Visual Saliency for Fixation Prediction", TIP(2016)
'Research > 컴퓨터비전, 영상처리' 카테고리의 다른 글
| [IQA] 콘트라스트 변화에 의한 품질의 변화를 고려한 알고리즘, RIQMC (0) | 2019.11.06 |
|---|---|
| [IQA] DoG 분해를 활용한 학습 기반 이미지 품질 평가 알고리즘, DOG-SSIM (0) | 2019.11.01 |
| [IQA] visual saliency를 활용한 이미지 품질 평가 알고리즘, VSI (7) | 2019.10.30 |
| 위상 합동(Phase congruency)의 의미와 엣지 검출 (9) | 2019.10.21 |
| [IQA] 왜곡으로 인한 artifact를 블러, 노이즈, 블락으로 분류해서 다룬 BNB (0) | 2019.10.07 |
| 슈퍼픽셀(superpixel)과 SLIC 알고리즘 활용 (0) | 2019.09.30 |
| 전역 선행성(global precedence)이란? (0) | 2019.09.03 |
| subthreshold, near-threshold, suprathreshold의 의미 (0) | 2019.09.03 |