visual saliency 모델은 이미지 내에서 시각적으로 중요한 부분들이 어딘지 또한 얼마나 중요한지를 예측해주는 알고리즘이다. visual saliency 모델은 크게 두 부류로 나눌 수 있다. 하나는 이미지 내에서 사람의 시선이 어디에 가장 많이 머물지를 예측해내는 방법이고, 또 다른 하나는 이미지 내에서 사람이 중요하다고 생각할 물체 또는 지역을 검출해내는 방법이다[3]. 전자를 FP(fixation prediction) 방식이라고 부르고, 후자를 SOD(salient object detection) 방식이라고 부른다. 오늘은 SOD 방식에 대해 알아보려고 한다.
salient object detection의 목적
SOD의 목적은 이미지 내에서 중요하다고 생각되는 물체를 검출해내는 것이다. 다른 말로 배경(background)에서 중요한 전경(foreground) 물체만을 분할해낸다. 아래 그림은 몇 개의 이미지에 대해 여러 개의 SOD 알고리즘들이 적용되어 산출된 saliency 맵들을 보여준다. SOD 알고리즘들이 배경과 중요한 전경 물체를 어느 정도 잘 분할해내는 것들을 확인할 수 있다. GT, 즉 ground-truth와 비교해서 F-DDS 모델이 산출한 saliency 맵은 큰 차이가 없다.

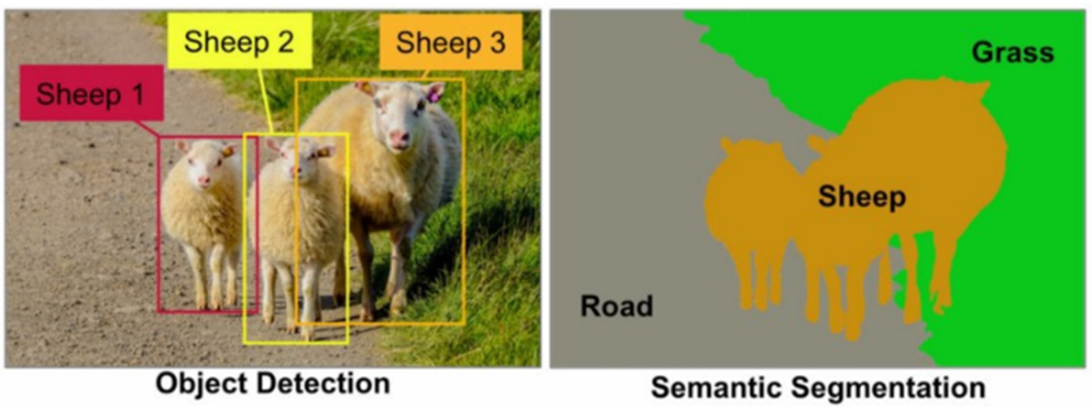
SOD 과제는 object detection, semantic segmentation 과제와 연관이 있지만 목적에서 분명한 차이가 있다. object detection 과제는 이미지 내에서 물체를 찾아서 바운딩 박스로 감싸주고 그 물체가 무엇인지 분류해내는 것을 목표로 한다. 반면 semantic segmentation 과제는 이미지 내 물체들을 의미있는 단위로 분할해준다. 아래 그림을 보면 object detection과 semantic segmentation의 목적의 차이를 쉽게 알 수 있을 것이다.
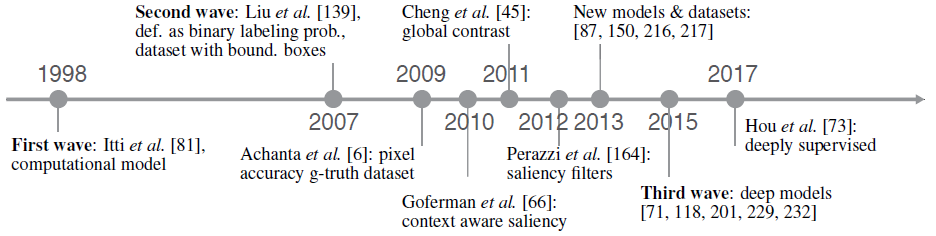
SOD의 발전사
Borji 등이 SOD 알고리즘에 대해 정리한 논문[4]에 의하면 SOD 알고리즘의 발전 역사에서 세 개의 사건을 주목할만하다고 한다. 첫번째 사건은 Itti 등이 visual saliency에 관한 계산 모델(computational model)을 1998년에 최초로 학계에 제안한 것이다. (엄밀히 따지면 Itti 모델은 FP 방식에 속하긴 하지만 Borji[4]는 SOD의 발전사를 정리함에 있어 FP와 SOD를 크게 구분짓지 않았다.)
두번째 사건은 2007년에 Liu 등이 visual saliency 과제를 이진 분할 문제(back ground와 foreground)로 정의한 것이다. visual saliency 과제를 object detection의 관점으로 보기 시작한 것이다.
세번째 사건은 2015년부터 딥러닝 기반 SOD 모델들의 출현이다. 특히 컨볼루션 신경망(CNN)의 부흥은 SOD에도 큰 영향을 미쳤다. 사실상 지금 개발되는 SOD 모델들을 거의 모두 CNN 기반이라고 볼 수 있다.
<참고자료>
[1] https://towardsdatascience.com/detection-and-segmentation-through-convnets-47aa42de27ea, Ravindra Parmar, "Detection and Segmentation through ConvNets"
[2] Zhao 등, "Optimizing the F-measure for Threshold-free Salient Object Detection", arXiv preprint arXiv:1805.07567 (2018).
[3] Borji 등, "Salient Object Detection: A Benchmark", IEEE Transactions on Image Processing, Vol. 24, No. 12, December 2015
[4] Borji 등, "Salient Object Dection: A Survey", Computational Visual Media, Vol. 5, No. 2, June 2019, 117-150.
'Research > 컴퓨터비전, 영상처리' 카테고리의 다른 글
| 전역 선행성(global precedence)이란? (0) | 2019.09.03 |
|---|---|
| subthreshold, near-threshold, suprathreshold의 의미 (0) | 2019.09.03 |
| 한계효용체감의 법칙이란? (7) | 2019.08.20 |
| [IQA] 미리 훈련된 CNN으로 얻은 특성맵들의 품질로 이미지의 품질을 평가하는 모델, DeepSim (0) | 2019.07.10 |
| 경험 품질에 관한 레이블, MOS(mean opinion score)와 DMOS(differential opinion score) (0) | 2019.07.05 |
| semantic segmentation의 목적과 대표 알고리즘 FCN의 원리 (16) | 2019.05.31 |
| JPEG 압축 제대로 이해하기 (19) | 2019.05.09 |
| visual masking이란? (0) | 2019.05.07 |