LeNet-5 => https://bskyvision.com/418
AlexNet => https://bskyvision.com/421
VGG-F, VGG-M, VGG-S => https://bskyvision.com/420
VGG-16, VGG-19 => https://bskyvision.com/504
GoogLeNet(inception v1) => https://bskyvision.com/539
ResNet => https://bskyvision.com/644
SENet => https://bskyvision.com/640
CNN 알고리즘들 중에서 이미지 분류용 알고리즘에 대해서 계속해서 포스팅을 하고 있다. 현재까지 LeNet-5, AlexNet, VGG-F, VGG-M, VGG-S에 대해 소개했었다.
오늘은 VGGNet에 대해서 글을 쓰려고 한다. VGGNet은 옥스포드 대학의 연구팀 VGG에 의해 개발된 모델로써, 2014년 이미지넷 이미지 인식 대회에서 준우승을 한 모델이다. 여기서 말하는 VGGNet은 16개 또는 19개의 층으로 구성된 모델을 의미한다(VGG16, VGG19로 불림). 이전에 포스팅한 VGG-F, VGG-M, VGG-S와는 차이가 있다. 그 모델들은 8개의 층을 가진 AlexNet과 유사한 모델들이다. 하지만 AlexNet와 같이 병렬적 구조로 이뤄지진 않았다.
역사적으로 봤을 때 VGGNet 모델부터 시작해서 네트워크의 깊이가 확 깊어졌다. 아래 그림을 참고하자.
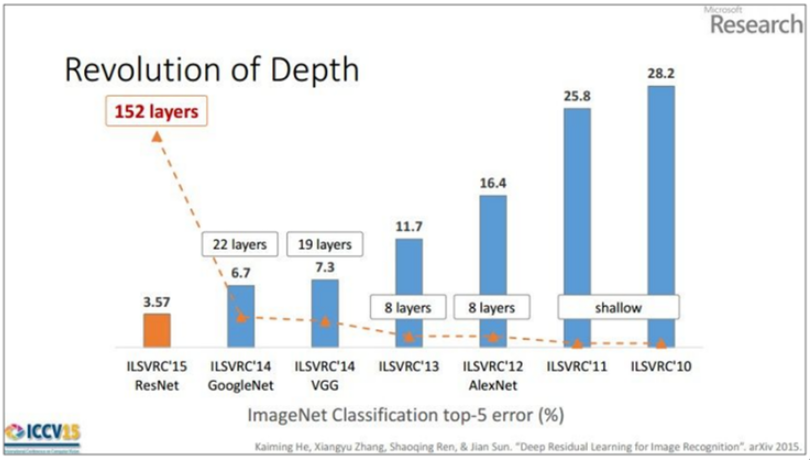
2012년, 2013년 우승 모델들은 8개의 층으로 구성되었었다. 반면 2014년의 VGGNet(VGG19)는 19층으로 구성되었고, 또한 GoogLeNet은 22층으로 구성되었다. 그리고 2015년에 이르러서는 152개의 층으로 구성된 ResNet이 제안되었다. 네크워크가 깊어질 수록 성능이 좋아졌음을 위 그림을 통해 확인할 수 있다. VGGNet은 사용하기 쉬운 구조와 좋은 성능 덕분에 그 대회에서 우승을 거둔 조금 더 복잡한 형태의 GoogLeNet보다 더 인기를 얻었다.
자, 그러면 VGGNet은 이전 모델들과 비교해서 어떤 점이 있는지 살펴보도록 하자. 이 VGGNet의 original 논문은 Karen Simonyan과 Andrew Zisserman에 의해 2015 ICLR에 게재된 "Very deep convolutional networks for large-scale image recognition"이다.
VGGNet의 구조
VGGNet의 original 논문의 개요에서 밝히고 있듯이 이 연구의 핵심은 네트워크의 깊이를 깊게 만드는 것이 성능에 어떤 영향을 미치는지를 확인하고자 한 것이다. VGG 연구팀은 깊이의 영향만을 최대한 확인하고자 컨볼루션 필터커널의 사이즈는 가장 작은 3 x 3으로 고정했다.
개인적으로 나는 모든 필터 커널의 사이즈를 3 x 3으로 설정했기 때문에 네트워크의 깊이를 깊게 만들 수 있다고 생각한다. 왜냐하면 필터커널의 사이즈가 크면 그만큼 이미지의 사이즈가 금방 축소되기 때문에 네트워크의 깊이를 충분히 깊게 만들기 불가능하기 때문이다.
VGG 연구팀은 original 논문에서 총 6개의 구조(A, A-LRN, B, C, D, E)를 만들어 성능을 비교했다. 여러 구조를 만든 이유는 기본적으로 깊이의 따른 성능 변화를 비교하기 위함이다. 이중 D 구조가 VGG16이고 E 구조가 VGG19라고 보면 된다.

VGG 연구팀은 AlexNet과 VGG-F, VGG-M, VGG-S에서 사용되던 Local Response Normalization(LRN)이 A 구조와 A-LRN 구조의 성능을 비교함으로 성능 향상에 별로 효과가 없다고 실험을 통해 확인했다. 그래서 더 깊은 B, C, D, E 구조에는 LRN을 적용하지 않는다고 논문에서 밝혔다. 또한 그들은 깊이가 11층, 13층, 16층, 19층으로 깊어지면서 분류 에러가 감소하는 것을 관찰했다. 즉, 깊어질수록 성능이 좋아진다는 것이었다.
VGGNet의 구조를 깊이 들여다보기에 앞서 먼저 집고 넘어가야할 것이 있다. 그것은 바로 3 x 3 필터로 두 차례 컨볼루션을 하는 것과 5 x 5 필터로 한 번 컨볼루션을 하는 것이 결과적으로 동일한 사이즈의 특성맵을 산출한다는 것이다(아래 그림 참고). 3 x 3 필터로 세 차례 컨볼루션 하는 것은 7 x 7 필터로 한 번 컨볼루션 하는 것과 대응된다.
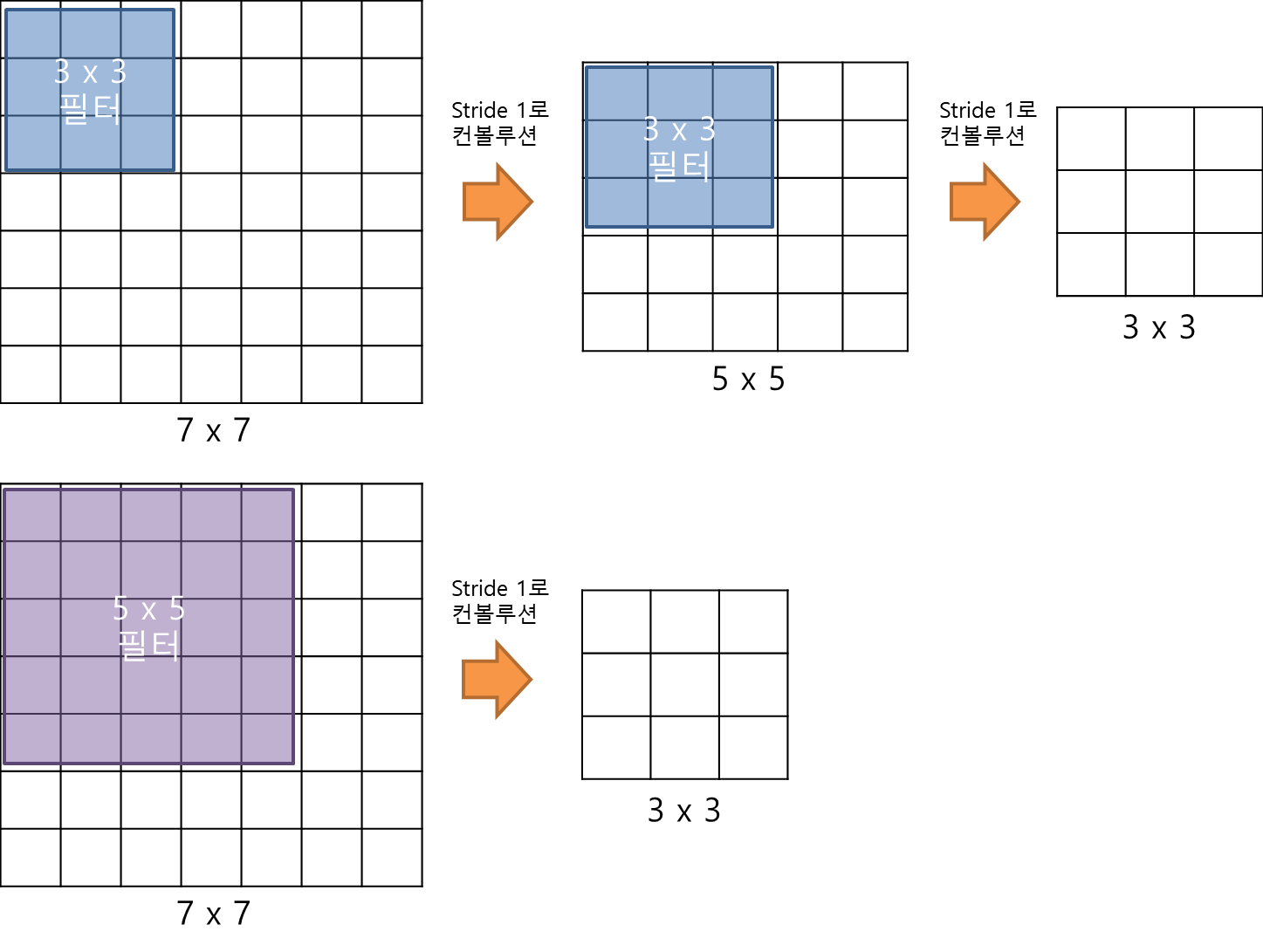
그러면 3 x 3 필터로 세 차례 컨볼루션을 하는 것이 7 x 7 필터로 한 번 컨볼루션하는 것보다 나은 점은 무엇일까? 일단 가중치 또는 파라미터의 갯수의 차이다. 3 x 3 필터가 3개면 총 27개의 가중치를 갖는다. 반면 7 x 7 필터는 49개의 가중치를 갖는다. CNN에서 가중치는 모두 훈련이 필요한 것들이므로, 가중치가 적다는 것은 그만큼 훈련시켜야할 것의 갯수가 작아진다. 따라서 학습의 속도가 빨라진다. 동시에 층의 갯수가 늘어나면서 특성에 비선형성을 더 증가시키기 때문에 특성이 점점 더 유용해진다.
VGG16 구조 분석
그러면 이제 VGG16(D 구조)를 예시로, 각 층마다 어떻게 특성맵이 생성되고 변화되는지 자세하게 살펴보자. 아래 구조도와 함께 각 층의 세부사항을 읽어나가면 이해하기가 그렇게 어렵지 않을 것이다.

0) 인풋: 224 x 224 x 3 이미지(224 x 224 RGB 이미지)를 입력받을 수 있다.
1) 1층(conv1_1): 64개의 3 x 3 x 3 필터커널로 입력이미지를 컨볼루션해준다. zero padding은 1만큼 해줬고, 컨볼루션 보폭(stride)는 1로 설정해준다. zero padding과 컨볼루션 stride에 대한 설정은 모든 컨볼루션층에서 모두 동일하니 다음 층부터는 설명을 생략하겠다. 결과적으로 64장의 224 x 224 특성맵(224 x 224 x 64)들이 생성된다. 활성화시키기 위해 ReLU 함수가 적용된다. ReLU함수는 마지막 16층을 제외하고는 항상 적용되니 이 또한 다음 층부터는 설명을 생략하겠다.
2) 2층(conv1_2): 64개의 3 x 3 x 64 필터커널로 특성맵을 컨볼루션해준다. 결과적으로 64장의 224 x 224 특성맵들(224 x 224 x 64)이 생성된다. 그 다음에 2 x 2 최대 풀링을 stride 2로 적용함으로 특성맵의 사이즈를 112 x 112 x 64로 줄인다.
*conv1_1, conv1_2와 conv2_1, conv2_2등으로 표현한 이유는 해상도를 줄여주는 최대 풀링 전까지의 층등을 한 모듈로 볼 수 있기 때문이다.
3) 3층(conv2_1): 128개의 3 x 3 x 64 필터커널로 특성맵을 컨볼루션해준다. 결과적으로 128장의 112 x 112 특성맵들(112 x 112 x 128)이 산출된다.
4) 4층(conv2_2): 128개의 3 x 3 x 128 필터커널로 특성맵을 컨볼루션해준다. 결과적으로 128장의 112 x 112 특성맵들(112 x 112 x 128)이 산출된다. 그 다음에 2 x 2 최대 풀링을 stride 2로 적용해준다. 특성맵의 사이즈가 56 x 56 x 128로 줄어들었다.
5) 5층(conv3_1): 256개의 3 x 3 x 128 필터커널로 특성맵을 컨볼루션한다. 결과적으로 256장의 56 x 56 특성맵들(56 x 56 x 256)이 생성된다.
6) 6층(conv3_2): 256개의 3 x 3 x 256 필터커널로 특성맵을 컨볼루션한다. 결과적으로 256장의 56 x 56 특성맵들(56 x 56 x 256)이 생성된다.
7) 7층(conv3_3): 256개의 3 x 3 x 256 필터커널로 특성맵을 컨볼루션한다. 결과적으로 256장의 56 x 56 특성맵들(56 x 56 x 256)이 생성된다. 그 다음에 2 x 2 최대 풀링을 stride 2로 적용한다. 특성맵의 사이즈가 28 x 28 x 256으로 줄어들었다.
8) 8층(conv4_1): 512개의 3 x 3 x 256 필터커널로 특성맵을 컨볼루션한다. 결과적으로 512장의 28 x 28 특성맵들(28 x 28 x 512)이 생성된다.
9) 9층(conv4_2): 512개의 3 x 3 x 512 필터커널로 특성맵을 컨볼루션한다. 결과적으로 512장의 28 x 28 특성맵들(28 x 28 x 512)이 생성된다.
10) 10층(conv4_3): 512개의 3 x 3 x 512 필터커널로 특성맵을 컨볼루션한다. 결과적으로 512장의 28 x 28 특성맵들(28 x 28 x 512)이 생성된다. 그 다음에 2 x 2 최대 풀링을 stride 2로 적용한다. 특성맵의 사이즈가 14 x 14 x 512로 줄어든다.
11) 11층(conv5_1): 512개의 3 x 3 x 512 필터커널로 특성맵을 컨볼루션한다. 결과적으로 512장의 14 x 14 특성맵들(14 x 14 x 512)이 생성된다.
12) 12층(conv5_2): 512개의 3 x 3 x 512 필터커널로 특성맵을 컨볼루션한다. 결과적으로 512장의 14 x 14 특성맵들(14 x 14 x 512)이 생성된다.
13) 13층(conv5-3): 512개의 3 x 3 x 512 필터커널로 특성맵을 컨볼루션한다. 결과적으로 512장의 14 x 14 특성맵들(14 x 14 x 512)이 생성된다. 그 다음에 2 x 2 최대 풀링을 stride 2로 적용한다. 특성맵의 사이즈가 7 x 7 x 512로 줄어든다.
14) 14층(fc1): 7 x 7 x 512의 특성맵을 flatten 해준다. flatten이라는 것은 전 층의 출력을 받아서 단순히 1차원의 벡터로 펼쳐주는 것을 의미한다. 결과적으로 7 x 7 x 512 = 25088개의 뉴런이 되고, fc1층의 4096개의 뉴런과 fully connected 된다. 훈련시 dropout이 적용된다.
(이 부분을 제대로 이해할 수 있도록 지적해주신 jaist님과 hiska님께 감사드립니다.^^)
15) 15층(fc2): 4096개의 뉴런으로 구성해준다. fc1층의 4096개의 뉴런과 fully connected 된다. 훈련시 dropout이 적용된다.
16) 16층(fc3): 1000개의 뉴런으로 구성된다. fc2층의 4096개의 뉴런과 fully connected된다. 출력값들은 softmax 함수로 활성화된다. 1000개의 뉴런으로 구성되었다는 것은 1000개의 클래스로 분류하는 목적으로 만들어진 네트워크란 뜻이다.
이미지 분류용 CNN 모델의 발전 과정을 추적해가는 과정이 꽤 흥미롭네요. 질문 있으시면 댓글로 남겨주세요. 혹시 제 이해가 잘못된 부분 있다면 지적 부탁드립니다.
참고자료
[1] https://laonple.blog.me/220738560542, 라온피플, VGGNet[1]
[2] https://laonple.blog.me/220749876381, 라온피플, VGGNet[2]
[3] https://reniew.github.io/08/, reniew's blog, Modern CNN
[4] https://cv-tricks.com/cnn/understand-resnet-alexnet-vgg-inception/, KOUSTUBH, "ResNet, AlexNet, VGGNet, Inception: Understanding various architectures of Convolutional Networks"
[5] http://www.vlfeat.org/matconvnet/models/imagenet-vgg-verydeep-16.svg
{kind=link}
[6] https://neurohive.io/en/popular-networks/vgg16/, Neurohive, "VGG16 - Convolutional Network for Classification and Detection"
[7] https://missinglink.ai/guides/convolutional-neural-networks/fully-connected-layers-convolutional-neural-networks-complete-guide/, missinglink.ai, "Fully Connected Layers in Convolutional Neural Networks: The Complete Guide"
(본문 내 쿠팡 파트너스 링크를 통해 물건을 구입하시면, 제게 소정의 수익이 생겨 더 좋은 글을 작성할 동기부여가 됩니다.)
'Research > ML, DL' 카테고리의 다른 글
| [강화학습] 마코프 프로세스(=마코프 체인) 제대로 이해하기 (11) | 2019.10.15 |
|---|---|
| 가장 간단한 군집 알고리즘, k-means 클러스터링 (0) | 2019.10.09 |
| 유유상종의 진리를 이용한 분류 모델, kNN(k-Nearest Neighbor) (6) | 2019.10.08 |
| [CNN 알고리즘들] GoogLeNet(inception v1)의 구조 (19) | 2019.10.07 |
| [CNN 알고리즘들] VGG-F, VGG-M, VGG-S의 구조 (2) | 2019.06.27 |
| [CNN 알고리즘들] AlexNet의 구조 (17) | 2019.03.11 |
| 딥러닝에 사용되는 softmax 함수 (0) | 2019.03.08 |
| 이미지 분류 모델 평가에 사용되는 top-5 error와 top-1 error (11) | 2019.03.06 |