파이썬 리스트 내 중복된 요소가 있는 경우, 중복된 요소는 제거하고 싶다면 어떻게 해야 할까요? 예를 들어, A = [1, 2, 1, 3, 2, 4, 4, 5, 1] 과 같은 리스트가 있다면, result_A = [1, 2, 3, 4, 5]를 찾고 싶은 상황입니다.
다양한 방법이 있겠지만, 제가 짠 로직은 다음과 같습니다. (아마 저 말고도 대부분 이렇게 짤 것 같습니다.)
1) result_A 라는 이름의 빈 리스트를 하나 만든다.
2) for 문으로 A 리스트 안에 요소를 하나씩 빼와서 그 요소가 result_A 안에 있지 않으면 result_A에 추가한다.
파이썬 코드로 구현하면 다음과 같습니다.
A = [1, 2, 1, 3, 2, 4, 4, 5, 1]
result_A = []
for i in A:
if i not in result_A:
result_A.append(i)
print(result_A)
위 코드를 실행하면 다음과 같이 중복된 요소들은 제거한 리스트가 생성됩니다.
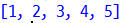
다른 방법1. numpy의 unique() 함수 활용
물론 다른 간단한 방법도 있습니다. numpy 패키지의 unique() 함수를 활용하는 것도 하나의 방법이 될 수 있습니다. 파이썬 리스트를 numpy.unique() 함수의 매개변수로 넣어주면 반환값은 넘파이 배열이기 때문에 만약 파이썬 리스트로 변환하고 싶다면 그 반환값을 list() 함수에 넣어주면 됩니다.
import numpy as np
A = [1, 2, 1, 3, 2, 4, 4, 5, 1]
result_A = list(np.unique(A))
print(result_A)

다른 방법2. set 활용
제 영혼의 친구 꼬장스카이비전님께서 아래 댓글에서 제안해주신 방법처럼 리스트의 데이터 타입을 set으로 변경합니다. 그러면 중복된 요소들이 제거되고 하나씩만 남게 됩니다. 그것을 다시 list() 함수에 넣어주면 됩니다.
A = [1, 2, 1, 3, 2, 4, 4, 5, 1]
print(set(A))
result_A = list(set(A))
print(result_A)

그런데 여기서 주의해야 할 점은 set 함수를 사용하는 경우에는 자동으로 오름차순으로 정렬된다는 점입니다.
A = [5, 2, 4, 3, 2, 4, 4, 5, 1]
print(set(A))
result_A = list(set(A))
print(result_A)
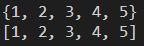
이렇게 졍렬되는 것을 원치 않는 경우에는 이 방법을 사용하시면 안 됩니다.
관련 글
- [python] 리스트의 중복된 요소들 중에 고유한 요소들을 알고 싶다면, numpy.unique()
(이 글은 2022-10-03에 마지막으로 수정되었습니다)
'Dev > python' 카테고리의 다른 글
| [python] 어떤 디렉토리 내에 존재하는 모든 이미지 파일들의 경로 리스트 만들기 (0) | 2021.01.08 |
|---|---|
| [python] 쉽고 간단하게 마스크 착용 유무 판별기 만들기 (106) | 2021.01.07 |
| [python] 랜덤 비밀번호 생성하기 (6) | 2021.01.06 |
| [python] 이번 달의 첫 시간과 마지막 시간을 알고 싶다면? 2021-01-01 00:00:00 과 2021-01-31 23:59:59 (2) | 2021.01.05 |
| [flask+jinja2] 행 개수 세기, 문자열 길이 산출하기, length 필터 (0) | 2020.12.18 |
| [python] 튜플의 값을 바꿔주려면? 리스트로 변환한 후 다시 튜플로 (0) | 2020.12.14 |
| [flask+jinja2] 중복되는 html 처리, {% include %} 사용 (6) | 2020.12.09 |
| [python] 리스트들의 교집합 찾기(set 활용) (0) | 2020.12.07 |